- Introduction
- Why offload?
- Why offloading didn't work before
- What Grace Blackwell brings to the table
- Offloading the MLP block
- The experiment
- Head-to-head: offloading vs activation checkpointing
- Memory
- Speed
- Deploying on real Grace Blackwell systems
- The general principle
- When full offloading breaks: Grok2
- How the tradeoff scales
- Composability
- Thank you
- Acknowledgements
Table of contents
TL;DR: We show that NVIDIA's Grace Blackwell NVLink C2C link can be used to offload MLP activations to host memory during training, replacing activation checkpointing with a faster alternative. On Qwen3-30B-3A, this yields a 6–13% end-to-end throughput improvement at roughly 0.5% additional peak memory. For models with very large MLP blocks, a selective variant recovers most of the benefit. We share our ablations, profiles, and the general principle behind the technique.
Introduction
It's been over six months since we finished publishing our first ever blog series on the Model Factory. The reaction from the community was overwhelming, and one thing became clear: there's an insatiable appetite for more insights into how models are built at frontier labs.
Luckily for us, the Model Factory has grown at an unprecedented rate in the time since we wrote our posts about it. Much like we predicted, the Model Factory continues to grow precisely because each sub-piece feeds into a larger system. For example, a slightly faster training codebase allows for larger scale reinforcement learning pipelines, which in turn leads to improved models for building code-execution environments.
Yet, one of the most rewarding things about the Model Factory's growth has been the variety of tips, tricks and techniques that we've picked up along the way. These techniques are typically aimed at improving one small piece of the overall Model Factory—say, our training codebase—but they tend to have an outsized impact. In fact, that's precisely why we like them so much.
Because we like these techniques so much, we've decided to speak about them to the wider world. Every so often, we will release a new post about one of these tools of the trade that we've found to be simply indispensable. We hope that by documenting these techniques we're able to pull back the curtain even further on the engineering behind frontier model building. Let's start with one of our favorites; NVLink C2C Activation Offloading.
Why offload?
Every large training run eventually runs into the same problem: you run out of HBM. As a model's forward pass progresses through its layers, it leaves behind a trail of intermediate activations, which are typically stored for gradient computations during the backwards pass. These activations pile up, layer after layer, until they're used and ultimately released during the backwards pass. And, unlike weights and optimizer states—which shard quite well across devices—there's not really much you can do about the size of activations on a per-device basis. We stress that, although well-known techniques like Tensor Parallelism and Context Parallelism can be used for activations, they're typically pretty inflexible and they naturally introduce communication overheads, so they certainly don't represent a silver bullet. This means that the space needed for activations eventually ends up dominating device memory, presenting a real pain point.
To get a sense of scale, let's consider a single SwiGLU-based MoE layer in a model like Qwen3-30B-3A. As a recap, SwiGLU computes , and the MLP block alone produces three large activation tensors needed for the backward pass: the gate projection output (, the input to SiLU), the up projection output (), and the SwiGLU intermediate (, the input to )—each scaling with batch size, sequence length, and the intermediate dimension (for MoE models, this is the number of active experts multiplied by the per-expert intermediate dimension, since each token's activations are materialized across all routed experts). For context, this is already a huge amount of memory: at a reasonable microbatch size, we measure roughly 3.7GB of MLP activations per layer (we derive this figure in "Offloading the MLP block"). Across all 48 layers, that's nearly 180 GB of activation memory on top of the model weights, optimizer states, and gradient buffers that already compete for the same HBM. At frontier scale, coping with this constraint often dictates your parallelism strategy, your microbatch size, and ultimately the achieved training throughput.
Of course, this is too big a problem to have been left unsolved for long, and the field of AI has a standard answer in the form of activation checkpointing. Instead of storing these large intermediates during the forward pass, activation checkpointing works by re-computing the intermediates on-the-fly during the backwards pass, allowing us to trade compute for memory savings. At this point, activation checkpointing is a standard technique, and we would expect that almost every large-scale training run uses it in some form. But activation checkpointing isn't free; every recomputed activation costs us FLOPs, which are expensive in terms of both time and energy. And this situation is even worse in the context of large MoE models; we're essentially re-running the MLP projection GEMMs (gate, up, and down projections across all active experts) for each layer twice.
At this point, we might look to other techniques that allow us to offload activations during training. Luckily, this approach is already well studied; both FSDP and ZeRO exist, after all. But these approaches only target the weights and the optimizer states, and not the intermediate activations. This leads to a natural question: can we offload activations?
If we could stash them in a secondary memory pool during the forward pass and pull them back during the backward pass—without interfering with compute—we'd get the memory savings of activation checkpointing without the recomputation tax. On previous hardware, this never worked—but NVIDIA's Grace superchips change the equation.
So how does offloading stack up against activation checkpointing (AC)? Both save the same steady-state memory—the difference is what you pay. AC pays with compute (rerunning the MLP forward); offloading pays with transient memory and NVLink C2C bandwidth. In what follows, we show that this trade is overwhelmingly favourable on Grace Blackwell hardware.
Why offloading didn't work before
Before we continue, it's worth highlighting why activation offloading hasn't been viable in the past. After all, offloading weights and optimizer states to host memory over PCIe is a well-established technique. What makes activations special?
The main issue is that activations are generated and consumed within a single training step. This means that we have to offload our intermediate activations incredibly quickly: the D2H transfer from one layer must complete before the next-next layer needs that buffer space. In practice, the offload overlaps with the following layer's forward compute, so the link must keep up with layer-by-layer compute, which PCIe Gen5 simply isn't capable of. For example, let's consider a typical H200 setup. The path to host memory in these settings is PCIe Gen5 16x, which provides roughly 64GB/s of unidirectional bandwidth. With several gigabytes of activation data per layer, the transfer time matches the forward compute time. There's just no margin.
The result is a snowball effect: each layer adds activations to the transfer queue before the previous layer's transfer has finished. The backlog grows with every layer, and training throughput collapses. We saw this firsthand in 2024 with our Monster codebase, where we used NVIDIA's Unified Memory to automatically offload activations to host memory via page migration and pre-emptively fetch them back during the backward pass. It worked in principle, but the profiles told the story: they were littered with device-to-host memcpys, page migrations, and all manner of other issues. Our step time exploded substantially, and we quickly realized it just wasn't viable.
This insight, it turns out, is all we need to work out when offloading activations is feasible: we simply need a good ratio of host-to-device bandwidth relative to the amount of compute offered by the platform. Concretely, let be the activation volume from layer , the host link bandwidth, and the next layer's forward compute time. The offloading scheme avoids a snowball if and only if:
With GB/s on PCIe Gen5, this inequality doesn't hold for any model of interest. It's worth noting that we can do certain things to reduce this snowball; for instance, we could block until each transfer completes, but this ultimately sacrifices the main benefit of offloading.
What Grace Blackwell brings to the table
So far, we've restricted our analysis to H200s. But the AI industry hasn't stood still, and NVIDIA's GB200 Super Chip is one of the premier accelerators. For the unfamiliar, Grace Blackwell is a system-on-a-chip architecture, pairing two Blackwell GPUs with a Grace CPU. These chips are connected via a chip-to-chip (C2C) NVLink connection. We note that the earlier Grace Hopper (GH) family of chips shares the same NVLink C2C interconnect, so the principles here apply to both families. But, for the sake of this article, we'll only concern ourselves with Grace Blackwell. It turns out that there's three properties that make these architectures interesting for activation offloading.
First, the GB family offers a huge amount of C2C bandwidth. The C2C link is rated at ~900 GB/s bidirectional, but there's a subtlety: NVIDIA quotes this per Blackwell GPU package, and each package contains two GPU dies sharing one HBM stack. So the effective per-die unidirectional bandwidth is GB/s in theory. In practice, we consistently measure GB/s—with current optimizations, we measure 82% of theoretical peak, with the rest consumed by overhead. That's still ~3x PCIe Gen5, and it's a stable figure across a range of tensor sizes. (A quick nvbandwidth or STREAM-style memcpy test is a good way for cluster teams to verify healthy C2C throughput before deploying offloading.) As an aside, although NVLink-C2C is nominally symmetric, we empirically observe that H2D transfers are consistently faster than D2H—likely due to differences in write-combining and prefetch behavior between the Grace and Blackwell memory controllers. We use the lower D2H figure for our feasibility analysis.
Second, C2C transfers consume no SM resources. A dedicated copy engine on the Blackwell die services the link, so data transfers run concurrently with compute kernels without stealing SM cycles. This means that we can overlap offloading with GEMMs without meaningfully dropping our compute throughput, though, as we'll see in what follows, there's a subtlety around HBM contention during memory-bound operations.
Third, Grace features 480 GB of LPDDR5x system memory per CPU, and each board has 1 Grace CPU and 2 Blackwell GPUs with 186 GB of HBM3e memory each. Even for a 48-layer model offloading three MLP activations per layer ( GB total), there's ample headroom. Of course, we have other contenders for CPU memory (data pipelining & prefetching etc) but in practice this isn't a constraint worth worrying about.
If we put all three together, then we can see that we've actually got the makings of something that simply wasn't possible before: overlapping activation offloading with layer-forward compute at sufficient bandwidth without running into the snowball effect.
Offloading the MLP block
As we've already mentioned, the natural target for this offloading is the MLP block. In principle, offloading every activation in a layer would yield the largest memory saving. We tried this, but it exceeded the NVLink C2C bandwidth budget for the models we tested, and it also demands more host memory than is practical. Instead, we focus on the MLP alone: when we say "full offload" we mean offloading every MLP activation tensor in the layer. To a certain extent, full MLP offloading is the natural place to start with this sort of optimization. After all, MLP activations are the largest per-layer memory consumer—they scale with , the FFN intermediate dimension (i.e., the hidden width of each MLP block)—and the most expensive to recompute. For dense models, is simply the MLP hidden width; for MoE models, it is , where is the number of active experts. We note here that there are some model architectures where full MLP offloading will simply exceed our bandwidth budget, but as we will see in our later analysis of Grok2, a selective offloading variant works equally well.
Let's start by offloading the full MLP layer. For a SwiGLU-based MoE layer, the backward pass requires the same three tensors introduced above: the gate projection output, the up projection output, and the SwiGLU intermediate. Together, the MLP activation memory per layer is:
where is the bytes-per-element (2 for BF16). For Qwen3-30B-3A, . We note here that a fused SwiGLU kernel can actually reduce this to only two tensors, as we can get away with only saving and and recomputing the rest on-the-fly. This drops the offload volume by around a third. This combination of fusing with offloading actually gives us the best of both worlds, as we transfer less data and also get various memory savings. However, for the sake of this post, we'll focus on the simple case and use the unfused, three-tensor approach.
By contrast, the recomputation cost that checkpointing pays is:
where is the number of active experts per token, d is the model hidden dimension, is the per-expert intermediate dimension (3 SwiGLU projections × 2 FLOPs/parameter). This is the compute that offloading eliminates. Even better for us, those redundant FLOPs consume real energy, so offloading is also the greener option.
The backward pass is heavier than the forward (gradients w.r.t. both activations and weights), which works in our favour: it gives the H2D reload extra time to complete. As an additional optimization, we can also skip offloading the last layer; after all, the backwards pass begins from the final layer, so there's zero overlap window between offloading and reloading the activations.
The experiment
In order to prove our ideas held in practice, we ran some experiments on 8 layers of Qwen3-30B-3A (out of 48) across 4 GB200 GPUs, with a microbatch size of 24 and a sequence length 4096. Qwen3-30B-3A, it turns out, is a good choice for this sort of work: the MoE architecture is relatively straightforward, making it a viable choice for quick experimentation. Our setup uses 4 GB200 Grace Blackwell superchips in a single node—the same superchips that make up GB200 NVL72 racks in production deployments. We decided to use only 8 layers out of 48 because the offloading pattern is per-layer: if it works without accumulating transfer debt on 8 layers, it works on 48. The microbatch size keeps the GEMMs compute-bound, which is the regime that matters at scale—and where the C2C copy engine can work without competing for HBM bandwidth.
Our experimental implementation hooks into PyTorch's saved-tensor mechanism, issuing D2H copies on a dedicated CUDA stream during the forward pass and H2D reloads on the same stream during the backward. We ensure that the host-side buffers are pinned (cudaHostAlloc), as although Grace Blackwell's C2C link with ATS lets the GPU reach pageable CPU memory directly, cudaMemcpyAsync still requires pinned memory to be truly non-blocking. This is a CUDA runtime constraint, not a hardware one, but it matters for our overlap experiments.
Because the copy stream is independent of the compute stream, transfers overlap with GEMMs without contention—provided those GEMMs are compute-bound. When a GEMM is memory-bound, its HBM traffic competes with the C2C copy engine for the same HBM bus, eating into the overlap. This is why we target compute-heavy phases: large matmuls that keep the SMs busy while the copy engine drains activations in the background. The approach is compatible with FSDP (the standard all_gather / reduce_scatter collectives run normally alongside the offload stream) and with torch.compile (compiled FxGraph regions are visible in the traces, interleaving cleanly with the asynchronous copies).
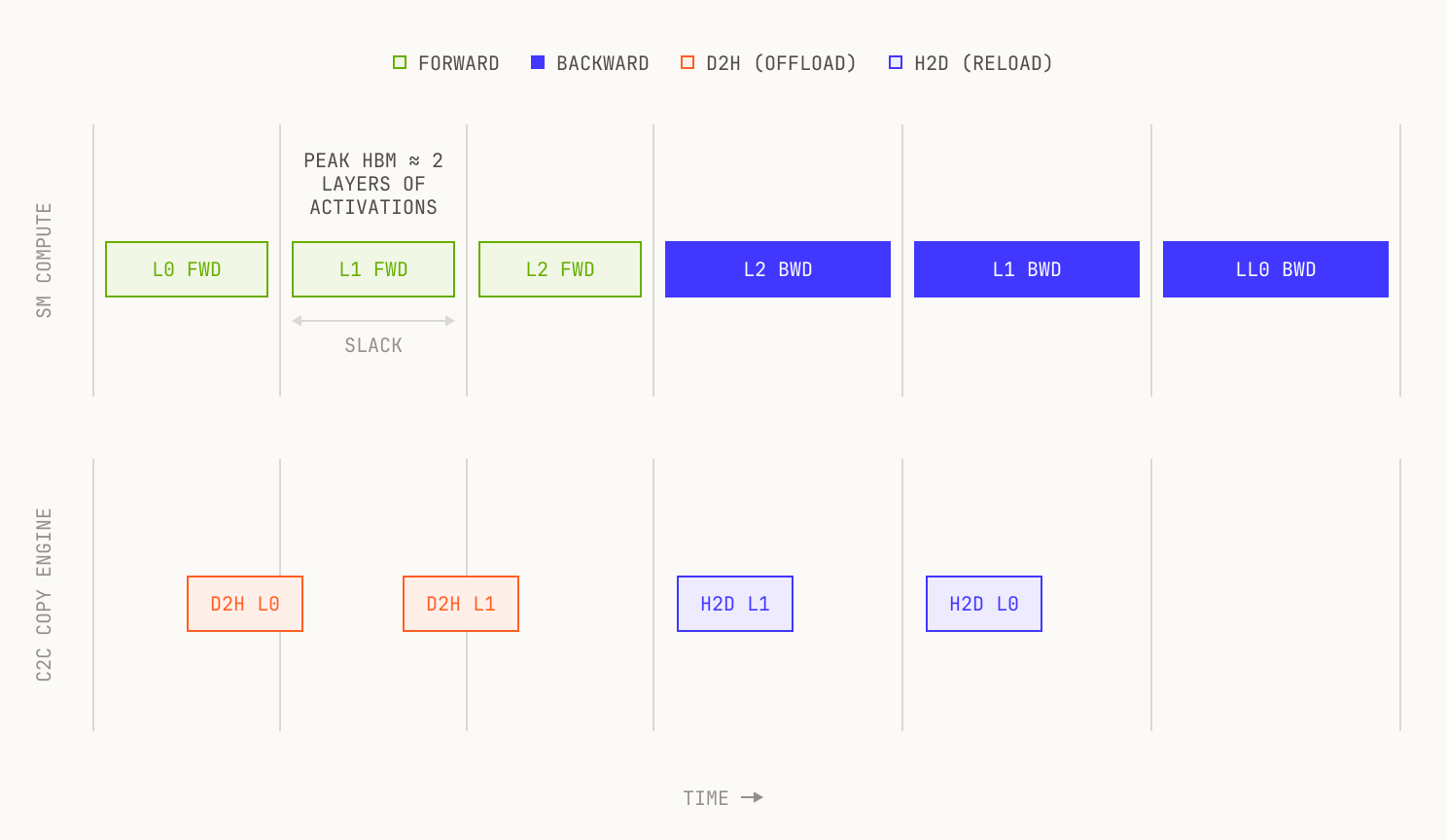
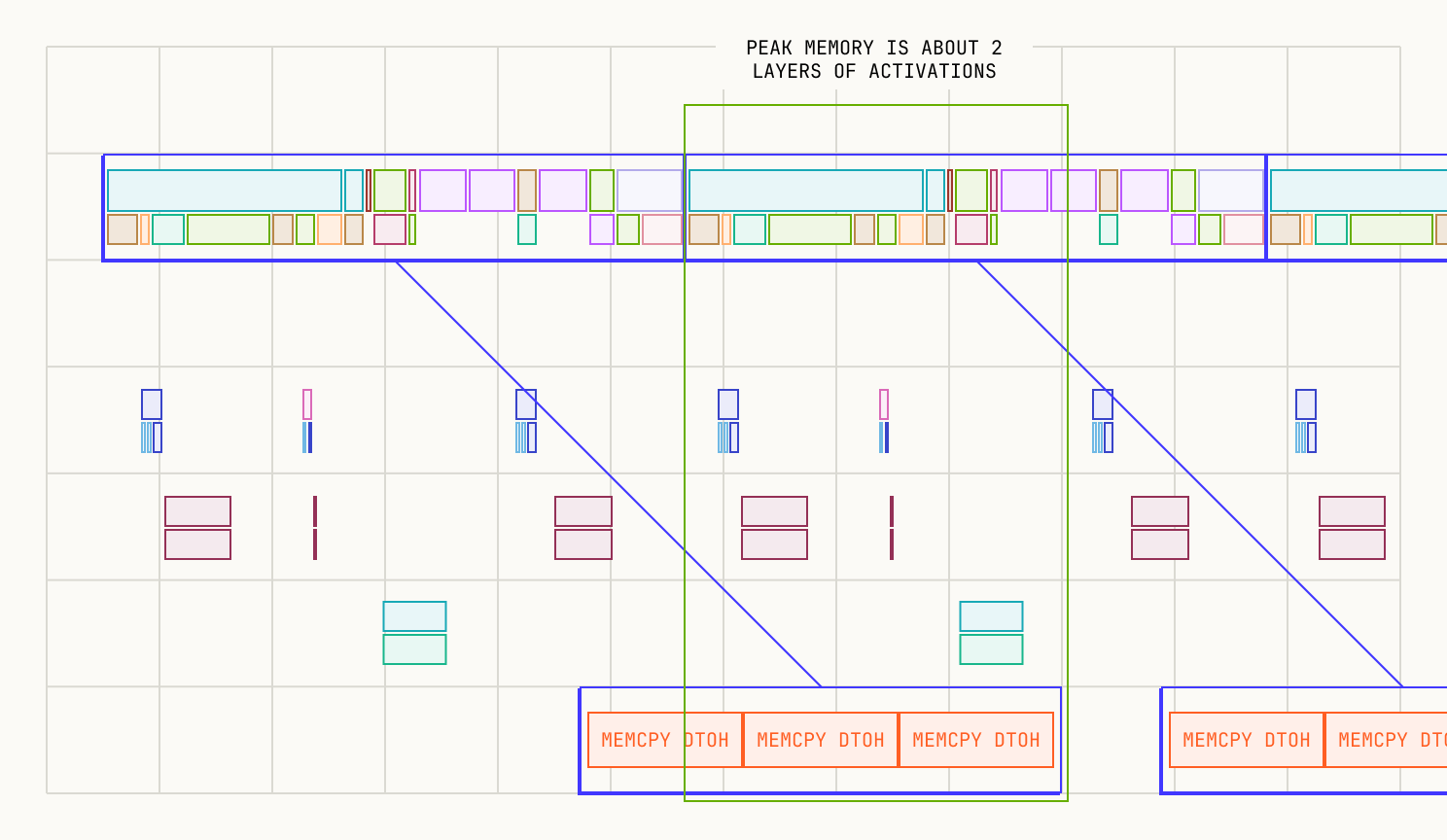
Pipeline timing diagram. SM compute (top lane) runs layer-forward and layer-backward kernels; the C2C copy engine (bottom lane) overlaps D2H offloads with the next layer's forward and H2D reloads with the current layer's backward. Peak HBM holds at most two layers of activations.
With all three SwiGLU activations offloaded per layer, the D2H transfer completes within the subsequent layer's forward compute time. The offload volume per layer is:
We measure the D2H transfer completing in ms, implying GB per layer. The layer forward time is ~22.5 ms, so holds—tight, but feasible.
The return trip is even less constrained: the H2D reload transfers the same 3.7 GB at GB/s ( ms), but the backwards provides a wider overlap window. In our traces, H2D completes well before the reloaded activations are consumed. D2H during the forward is the binding constraint. If an H2D transfer were to run long, the backward would stall on a cudaStreamSynchronize until the reload completes—correctness is preserved, but the overlap benefit is lost for that layer.
The profile below confirms this. D2H transfers (red boxes) complete well before the next layer's forward finishes. Peak HBM holds at most two layers of activations: the one being computed and the one being drained.
Qwen3-30B-3A MLP offload profile. D2H transfers (red boxes) complete well within each layer's forward compute window. Peak HBM holds at most two layers of activations.
For architectures with very large , the full MLP offload may exceed the layer forward time; we detail the fallback (offloading fewer tensors) in the Grok2 analysis below.
Head-to-head: offloading vs activation checkpointing
As mentioned in the introduction, both offloading and activation checkpointing (AC) save the same steady-state memory—the difference is what you pay. Let's now quantify that difference.
Memory
Let's start with memory. For our 8-layer setup, we measured the following:
- Peak allocated memory: 124.01 GB (offloading) vs 120.38 GB (activation checkpointing)—a difference of +3.63 GB, or roughly +3%.
- Steady-state minimum: 17.03 GB for both approaches—identical, as expected.
- "Triangle" height (peak minus min): 106.97 GB vs 103.35 GB—again, +3.63 GB (+3.5%).
It turns out that this +3% difference comes from the in-flight D2H buffer; one layer's activations are still in HBM while being transferred. At 20 ms × 185 GB/s = 3.7 GB, this matches the observed difference exactly.
Crucially, this overhead is constant (i.e. it holds no matter how many layers we're using for offloading). This means that the fractional overhead scales inversely with the number of layers:
where covers weights, optimizer states, gradients, and non-MLP activations. In our 8-layer experiment, , but the actual overhead is only 3% because is large. For the full 48-layer model, and the actual overhead drops to approximately 0.5%. For a 96-layer model it would be even less. In other words, the deeper the model, the better the deal.
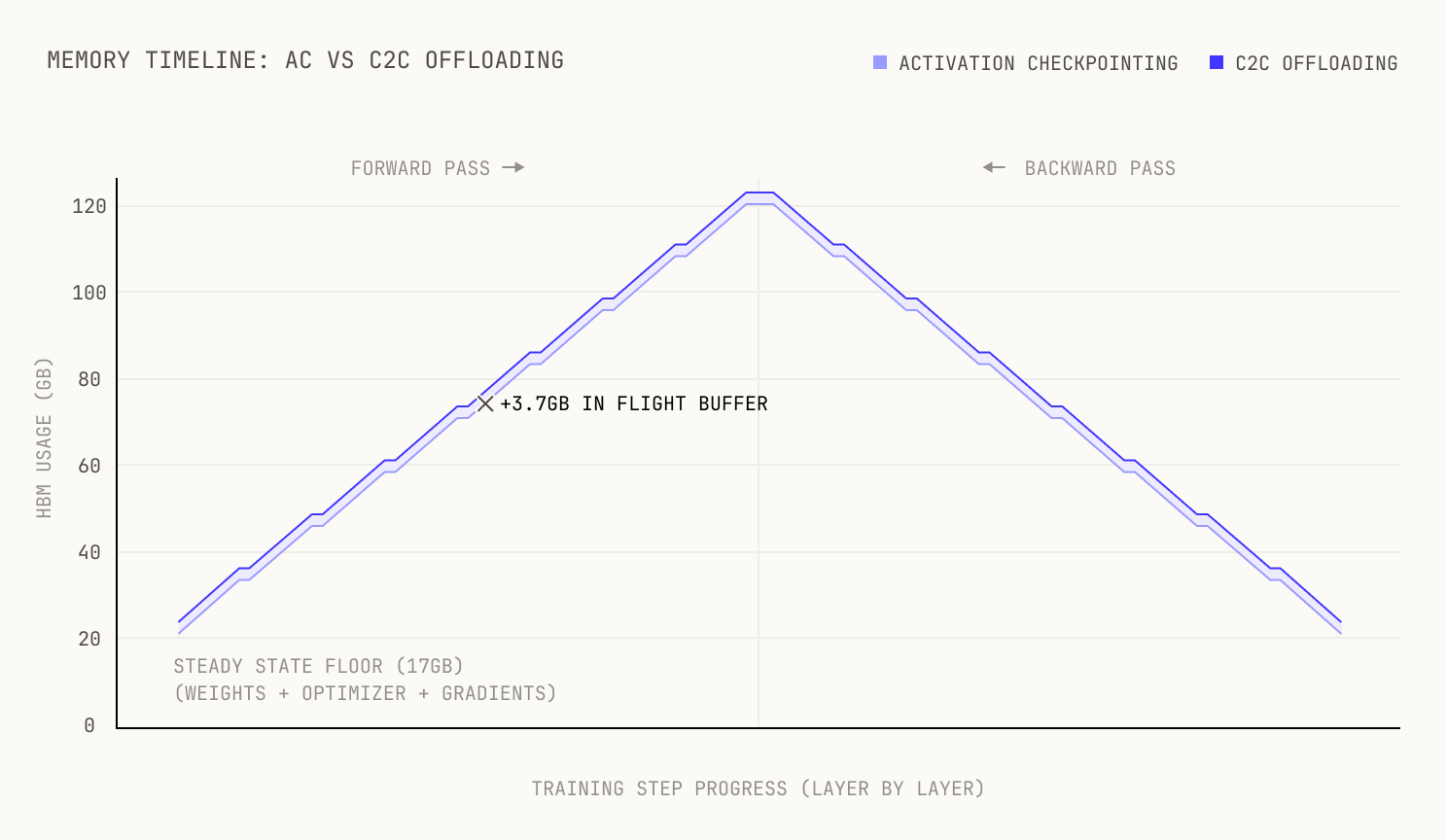
Memory timeline over one training step. Both approaches share the same steady-state floor; offloading adds a constant +3.7 GB in-flight buffer (one layer's activations being drained via C2C).
One caveat is that there can be substantial discrepancies between the measured peak memory and the allocated peak memory. This discrepancy is primarily due to allocator fragmentation, although PyTorch's CachingAllocator normally does a good job at minimizing this gap. In our experiment, actual memory was 160.86 GB vs 131.45 GB for AC—a 22% gap. This is solvable via pre-allocated fixed buffers for the in-flight data, and in distributed settings with FSDP the smaller per-rank state gives the allocator an easier time. This does not appear to be an issue at scale. This discrepancy is primarily due to allocator fragmentation, although PyTorch's CachingAllocator normally does a good job at minimizing this gap. In our experiment, actual memory was 160.86 GB vs 131.45 GB for AC—a 22% gap. This is solvable via pre-allocated fixed buffers for the in-flight data, and in distributed settings with FSDP the smaller per-rank state gives the allocator an easier time. This does not appear to be an issue at scale.
Speed
The forward pass is identical, as D2H transfers don't consume SMs. The win shows up in the backward pass: AC must recompute the MLP activations before computing gradients, while offloading simply reloads them from Grace memory via H2D on the copy engine. No SM cycles stolen.
We tested on 8 layers (out of 48) so that the experiment fits on a single 4-GPU node; the offloading pattern is per-layer, so if it works without accumulating transfer debt on 8 layers it works on 48. Averaging across all layers, offloading reduces backward time by ~7-8% compared to AC, with identical forward times. The representative middle layers show a larger gain of ~13%, but this speedup is not uniform: layers closer to the edges of the model see smaller improvements due to warm-up and cool-down effects, bringing the cross-layer average to ~7-8%.
For our 8-layer model, the end-to-end step time improves by ~4.3%. The gap between the ~7-8% per-layer gain and the 4.3% end-to-end figure is because the 8-layer model has proportionally large constant overhead (embeddings, unembeddings, loss computation) that dilutes the per-layer gains. For deeper models this constant overhead becomes negligible and the end-to-end speedup converges toward the per-layer gain, giving an expected 6–13% improvement. We derive the scaling properties below.
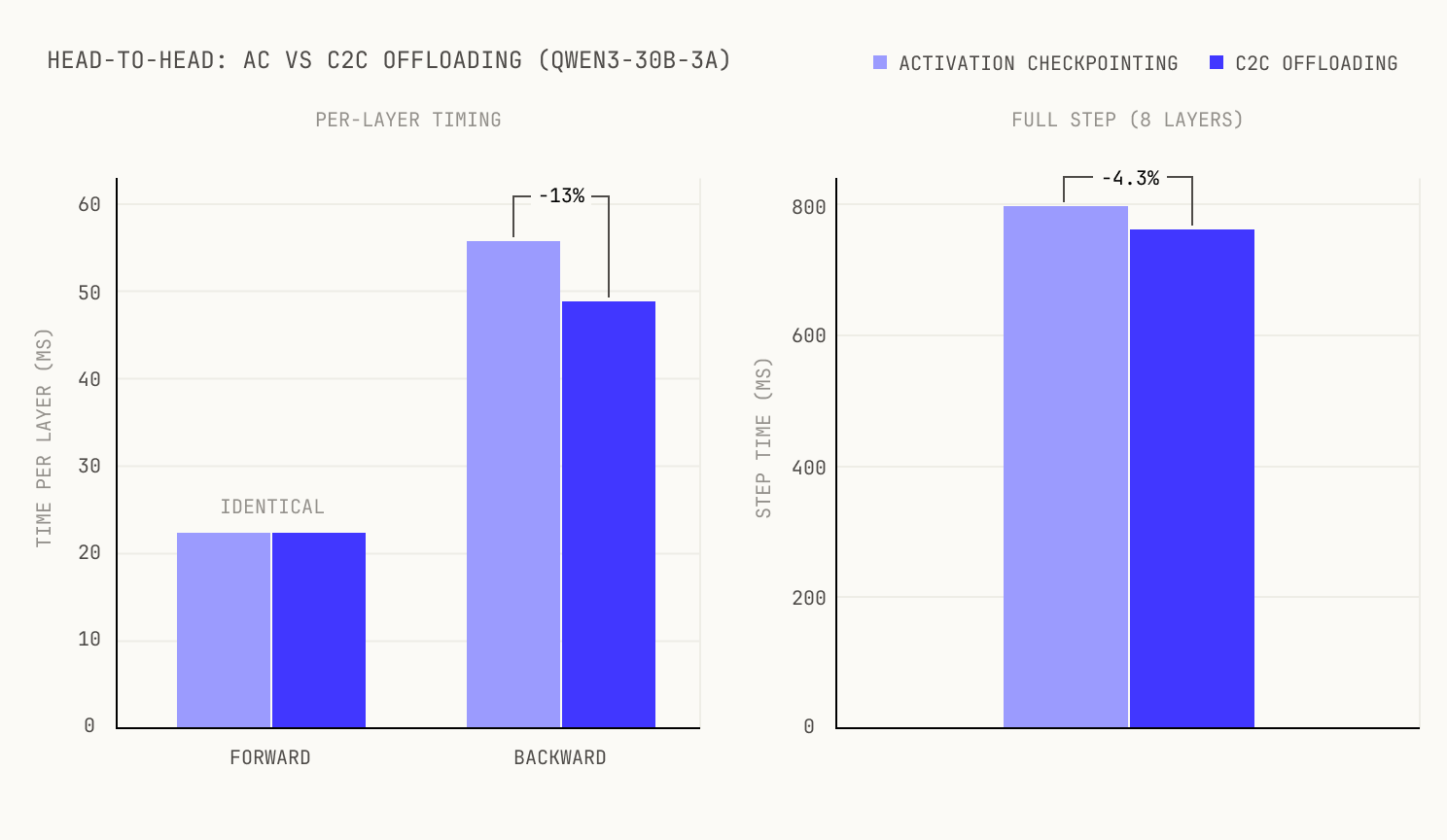
Head-to-head timing comparison for a representative middle layer. Left: relative per-layer forward (identical) and backward improvement. Right: relative end-to-end step time improvement over 8 layers.
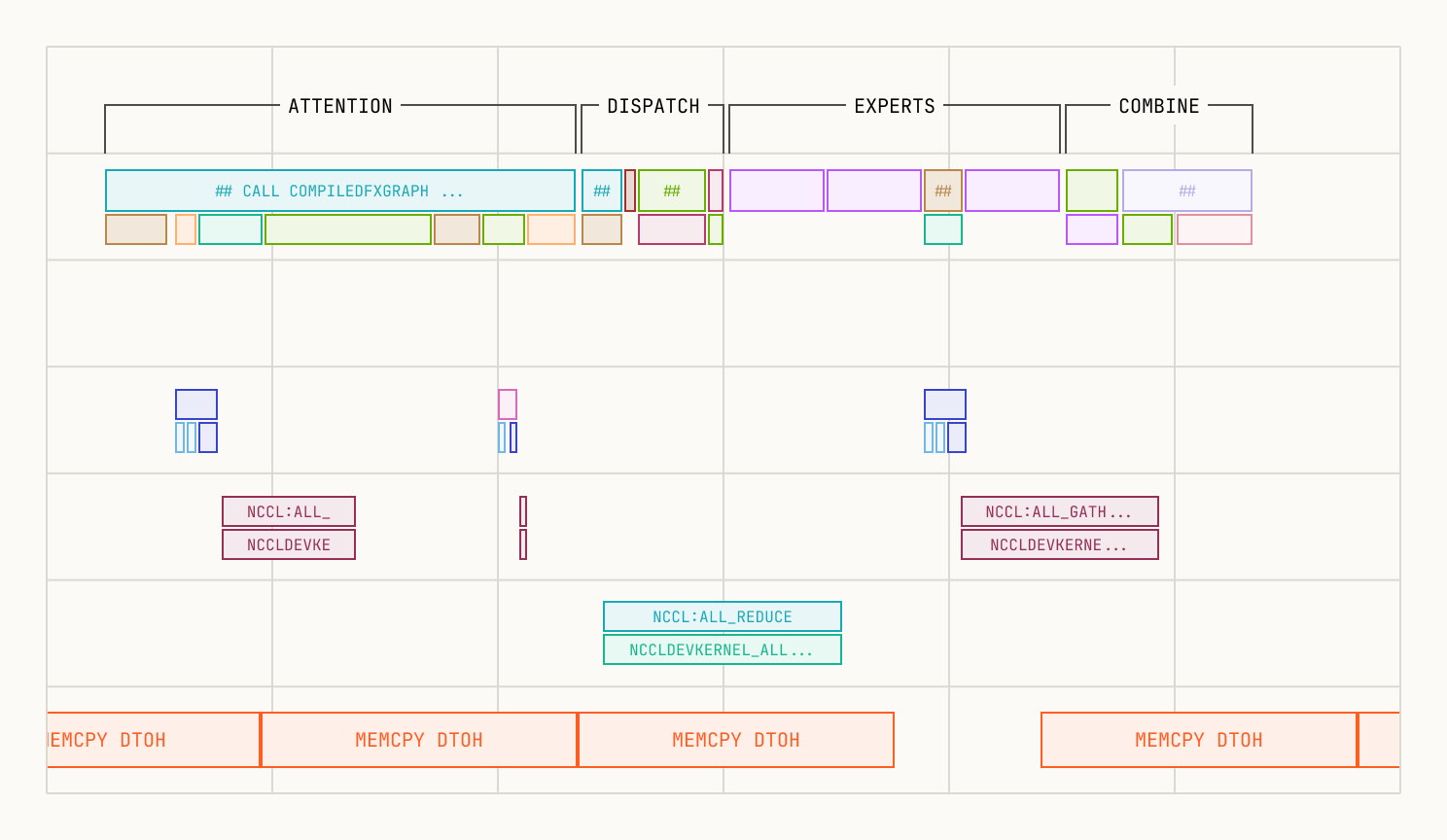
The profile below shows the per-layer timing in detail. You can see the D2H transfers from each layer completing well within the compute window, with no idle gaps on the SM timeline.
Per-layer timing detail showing D2H transfers overlapping with compute kernels. No idle gaps appear on the SM timeline.
The bottom line: for Qwen3-30B-3A at full depth (48 layers), offloading trades ~0.5% peak memory for a projected 6–13% throughput improvement. On a 90-day pre-training run, the midpoint of that range (~7%) translates to roughly 6 days of wall time saved.
Deploying on real Grace Blackwell systems
We have validated this technique on GB200 Grace Blackwell hardware. For teams looking to deploy C2C offloading in production, the key infrastructure prerequisites are: (1) C2C must be enabled in the system firmware (this is the default on GB200 NVL configurations), (2) host buffers must be pinned via cudaHostAlloc to ensure truly non-blocking cudaMemcpyAsync transfers, and (3) a basic C2C bandwidth health check (e.g. running nvbandwidth or a STREAM-style memcpy test) should confirm that each superchip achieves the expected ~185 GB/s D2H throughput before starting a training run.
The general principle
The scheme lives or dies on one constraint: the D2H transfer must finish within one layer's forward time, or the snowball returns. And the budget isn't just the MLP forward—it's the entire layer, including attention and communication. That non-MLP compute is free slack, and how much slack you get depends on the architecture. The D2H transfer time for all three SwiGLU activations is:
The layer forward time is the sum of MLP GEMMs ( FLOPs/token for SwiGLU with active experts), attention ( FLOPs/token, which depends on the sequence length ), and communication overhead. Since appears in both the transfer volume and the compute time, it cancels from the inequality, and the condition depends primarily on model architecture and hardware. Rearranging gives a threshold on :
where is the device's peak compute throughput. Note that this formula assumes a compute-bound regime; in general, the GEMM forward time is , where is the GEMM memory-traffic time and dominates in the memory-bandwidth-bound regime of the GEMM roofline. We also note that the attention contribution FLOPs grow quadratically with the sequence length, whilst both MLP FLOPs and the offload volume grow linearly; this potentially gives us more room to absorb the D2H transfer.
However, not all models are feasible for MLP offloading. One model—with a disproportionately large MLP—is Grok2.
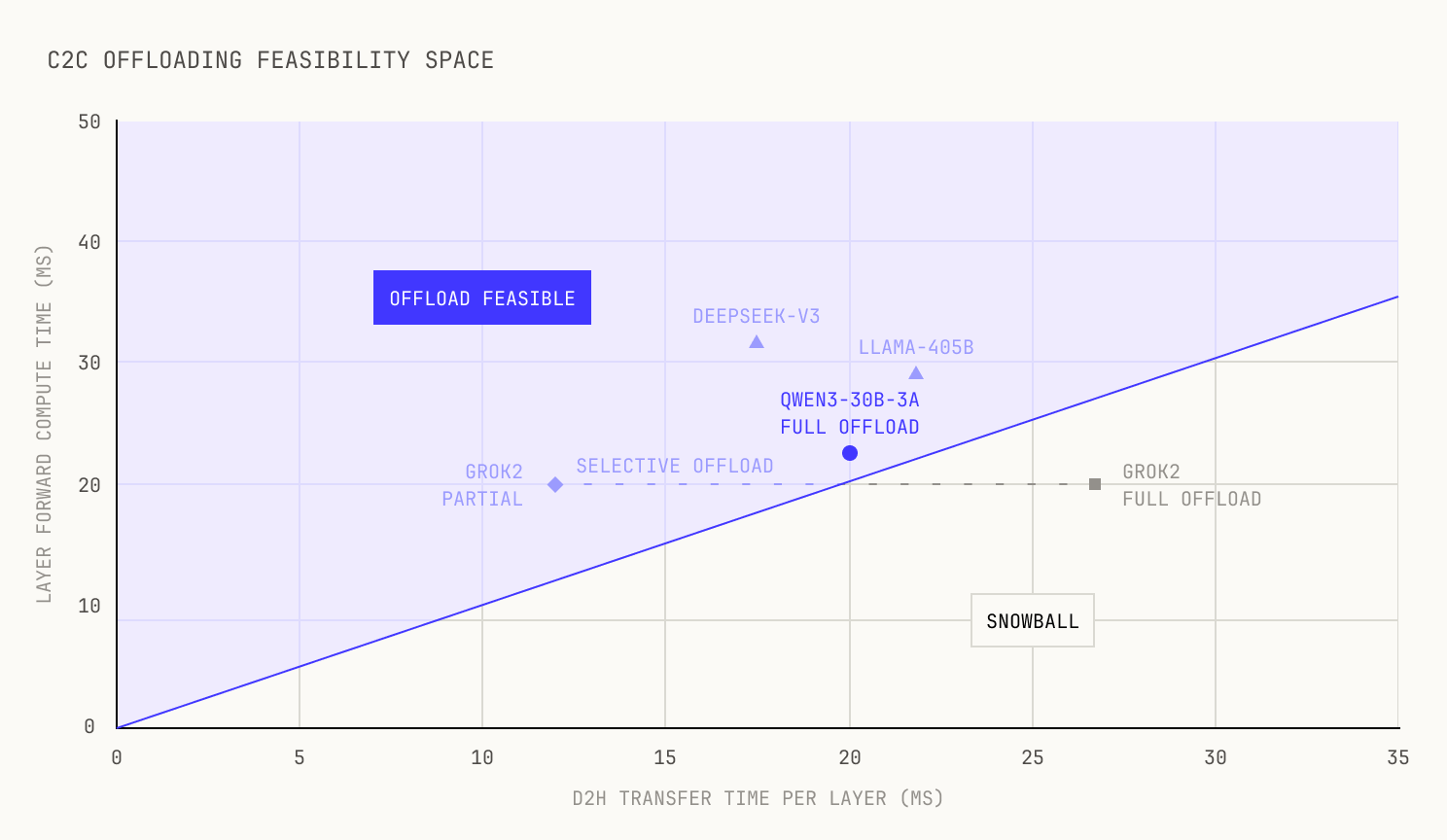
Feasibility space for C2C offloading. Models above the diagonal (D2H time < layer forward time) can offload without snowballing. Qwen3-30B-3A sits just above the boundary—feasible, but tight without attention slack; Grok2 requires selective offloading to move below the boundary.
When full offloading breaks: Grok2
Grok-2 is a prime example of a model that breaks full MLP offloading. It features a substantially larger MLP where each activation tensor is roughly 1.5 GB; with three per layer, the total reaches approximately 4.5 GB. At a transfer speed of 180 GB/s, the Device-to-Host (D2H) transfer takes ~25 ms, which exceeds the layer's forward pass time. This "snowball effect" is immediately visible in the profile:
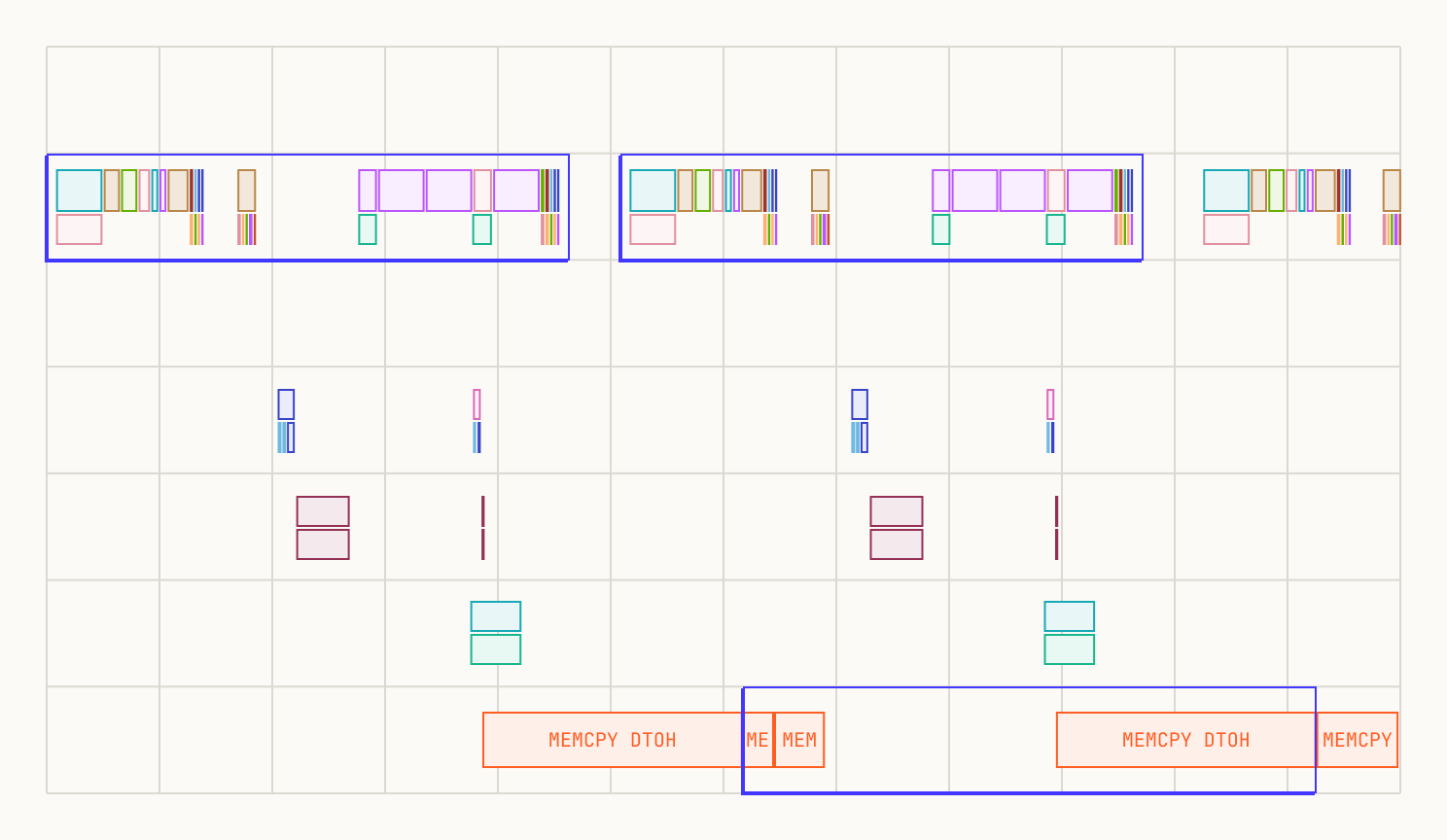
Grok2 full MLP offload showing the snowball effect. D2H transfers from each layer spill into the next layer's forward window, creating a growing backlog.
To address this, we can employ a different selective offloading strategy. Instead of offloading every intermediate tensor within the MLP, we offload only a subset of activations across the entire layer. By overlapping these smaller transfers with ongoing computations, we prevent the backlog from forming.
One effective solution is to offload specific activations from the attention block. There are several candidates for offloading, so the optimal choice depends on the specific hardware setup. In our case, we chose to offload:
- The transformer layer input.
- The attention output projection layer activations.
- Only one activation from the MLP (for the , to overlap with computation more).
By distributing the D2H transfers throughout the forward pass, we eliminated the primary MLP bottleneck.
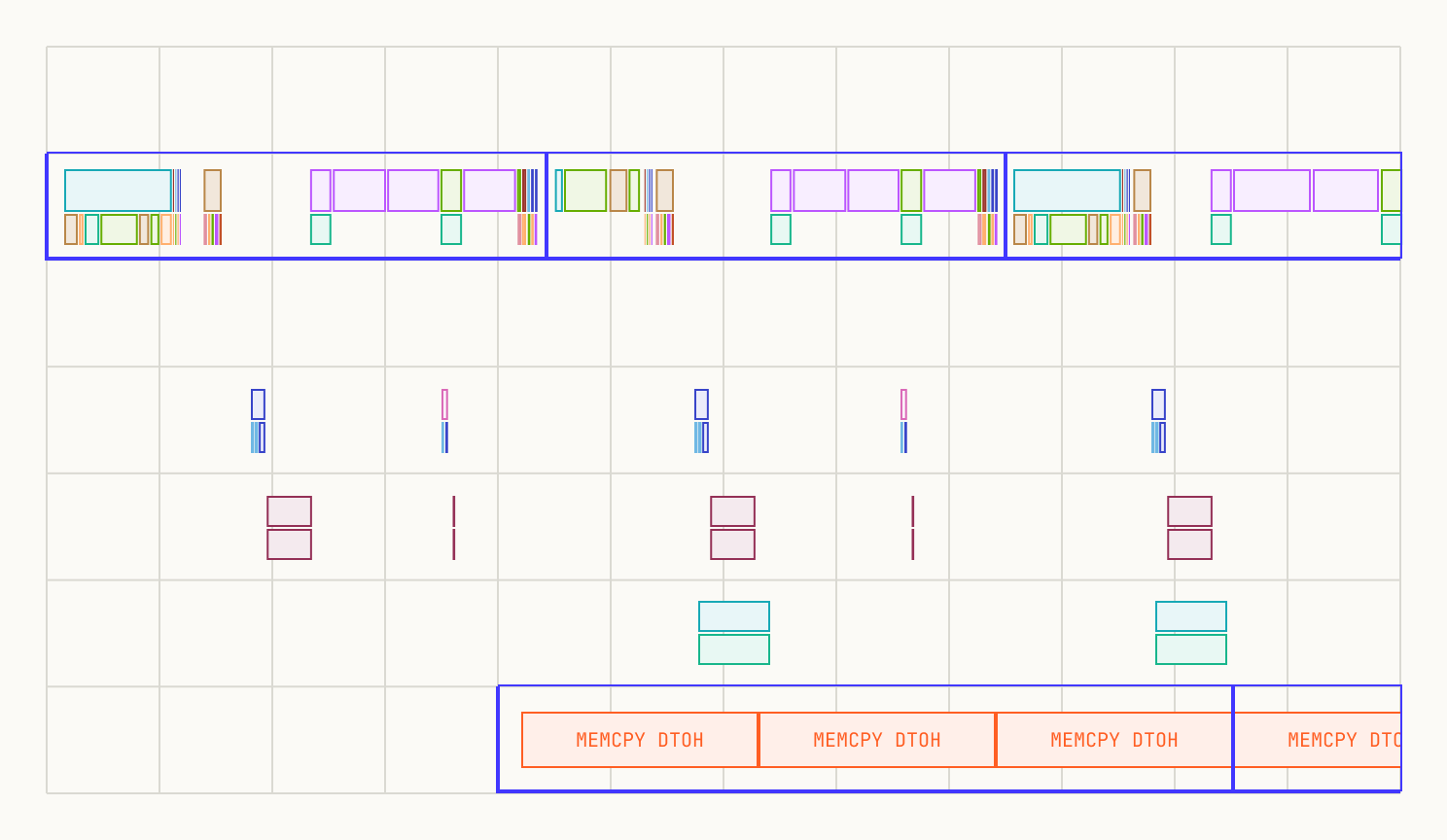
Selective offloading ensures D2H transfers stay within the layer's forward pass time.
As shown in the plot, the offloading stage now takes slightly less time than the forward pass, making the process feasible. In this configuration, we successfully offloaded about 2 GB per layer. Additionally, this approach provides a window to offload supplementary data between the attention and MLP phases.
Ultimately, this illustrates that offloading is a trade-off. Depending on the specific constraints, different strategies can be developed to balance memory savings with computational throughput. Moreover, offloading and activation checkpointing can be combined, allowing for recomputation from reloaded activations to avoid a full recomputation cycle.
How the tradeoff scales
We can now look at our full results.
| Qwen3-30B-3A | Grok2 (full) | Grok2 (partial) | |
|---|---|---|---|
| Offload volume per layer | 3.7 GB | 4.84 GB | 2.15 GB |
| D2H time (% of layer fwd) | ~89% | ~119% | ~62% |
| Fits in layer forward? | Yes | No | Yes |
| Memory overhead (48L) | ~1/L | — | ~1/L |
Note: We did not profile an AC baseline for Grok2, so the Grok2 columns compare full offloading against selective offloading rather than against AC. The 12% improvement is full-vs-partial; the partial-vs-AC comparison remains future work, because it requires a more granular AC implementation.
We can make several observations from this table. First, we can see that the in-flight buffer does, indeed, add one layer's worth of activations leading to a fractional overhead of at most fractional overhead (~2% for 48 layers, ~1% for 96).
Equally, we can see that there's a strong improvement in step time for this technique. Specifically, let be the per-layer recompute time eliminated. The recompute saving gives a lower bound on the fractional speedup:
Averaging across all layers, the backward gain is ~7–8%. For a sufficiently deep model, the end-to-end improvement converges toward this per-layer average as the constant overhead (embeddings, loss) is amortized. This is why our 8-layer experiment shows only 4.3% e2e despite the larger per-layer gain.
Lastly we note that, for a sufficiently deep model, cancels out; the speedup is depth-independent, while memory cost scales as . The deeper the model, the better the saving. For Qwen3-30B-3A at 48 layers, ms saved per step (where is the average per-layer saving) at a constant 3.7 GB memory cost. This makes C2C offloading particularly attractive for the deep, narrow MoE architectures that are popular in frontier open-source models today (DeepSeek-V3, Qwen3-MoE, GLM-5). Additionally, we note that C2C offloading applies equally to dense models where the generally smaller makes the feasibility condition easier to satisfy.
Composability
A technique that doesn't compose with production parallelism isn't very useful. The good news is that C2C offloading drops cleanly into existing distributed sharding strategies. In our traces, FSDP's all_gather / reduce_scatter run on the NIC alongside the C2C copy engine without interference. Tensor parallelism is unaffected (the offload operates on per-rank activations post-TP), and expert parallelism is likewise orthogonal (the offload targets post-dispatch activations). On paper, it also appears that Pipeline parallelism would work well with C2C offloading too: offloading could help fill pipeline bubbles, as we could use the otherwise idle time to transfer stored activations between host and device memory. However, this remains purely hypothetical on our part, as we have not yet validated this combination empirically.
Gradient accumulation composes naturally too: each microbatch's forward/backward offloads and reloads independently, and the in-flight buffer cost remains one layer's worth per microbatch (the previous microbatch's activations are fully drained before the next begins). In fact, activation checkpointing and offloading are pretty orthogonal, and it is possible to combine the two approaches into a hybrid strategy. In short, C2C offloading is additive: we can drop it into an existing FSDP + TP + EP + PP stack without needing to rearchitect anything at all.
Thank you
Thanks for reading! If you're interested in working on problems like these, we're hiring across many teams at Poolside—we'd love to hear from you.
Acknowledgements
We would like to thank the Poolside Architecture team for fruitful conversations around NVLink C2C offloading. We would also like to thank our partners at NVIDIA, including the NVIDIA Inception program for their support and technical expertise on this blog post.