- Running inference and evaluations inside the Model Factory
- Introduction
- Why Atlas: creating an excellent inference implementation
- How Atlas: producing compounding benefits through flexibility
- Where Atlas: optimizing inference across platforms
- When Atlas: deploying inference in the Factory
- Evaluations
- Thank you
- Acknowledgements
Table of contents
Running inference and evaluations inside the Model Factory
TL;DR: We present the details of how we run inference and evaluations at Poolside. We first introduce our inference codebase (known as Atlas) and explain how Atlas's current design came to be. We then describe how Atlas is structured, before we move on and discuss how we implement inference across a wide range of hardware platforms. Then, we describe how we deploy and serve inference as part of the Model Factory. Finally, we conclude by discussing how we use Atlas in tandem with our evaluations platform to robustly judge our models during pre-training and beyond.
Introduction
In our previous posts, we've discussed everything from our data pipelines up to code execution. But none of these tools, useful as they are, amount to much if we can’t serve our models to our internal and external clients. Moreover, the entire exercise is moot if the models themselves aren’t high quality.
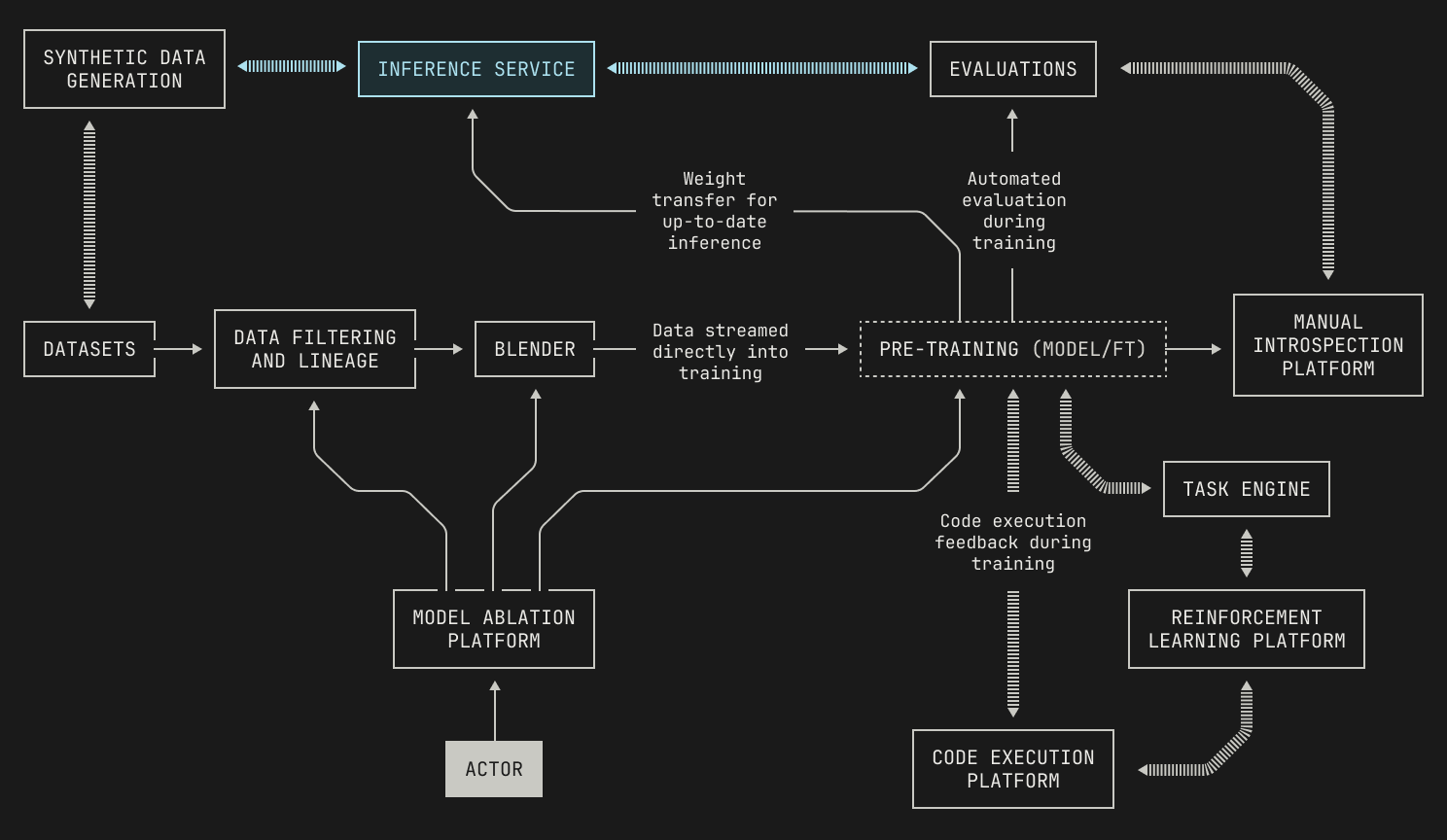
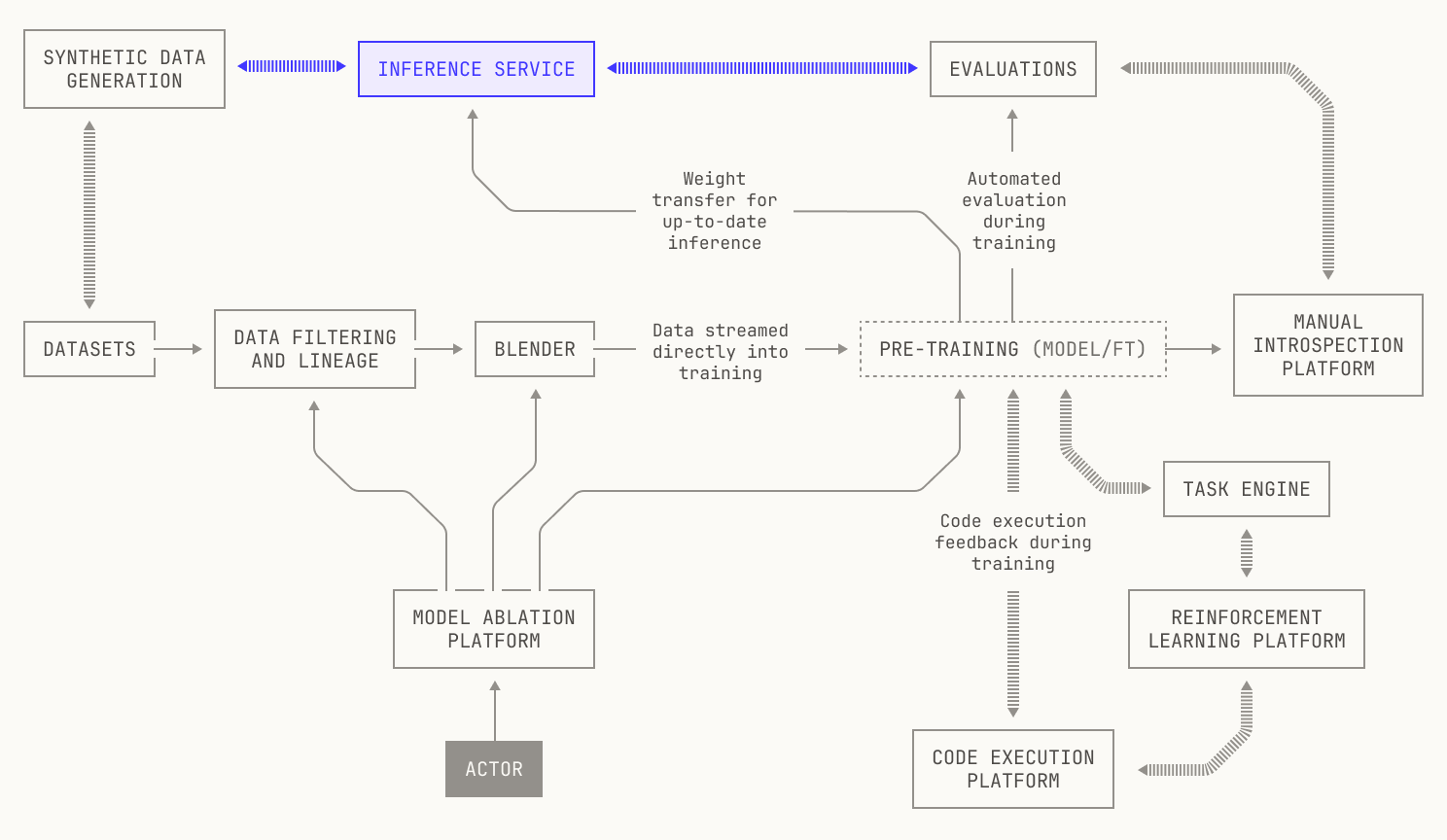
In this post, we discuss our systems for inference and evaluation. We begin by discussing Atlas, our inference codebase—specifically, we explain why we designed Atlas in its current form by describing the key principles behind a high-quality inference codebase. We then dig into how Atlas is structured in practice, and how we use it to run inference at scale. Along the way, we’ll talk about how we implement inference on both GPUs and Trainium hardware. We’ll then talk about how we deploy and schedule inference jobs on our cluster, before we conclude with a discussion of how our inference and evaluations platforms work together.
Why Atlas: creating an excellent inference implementation
Before we get into how Atlas helps us achieve our goals, let’s discuss why Atlas exists in its current form and what problems it attempts to solve. After all, attempting to understand a system without understanding why it exists is rarely a good idea.
Inference serves many roles at Poolside. Put simply, inference acts as the primary way that we interact with our models: we send requests, we get responses back, and we continue until we're satisfied. But what we expect out of this interaction changes entirely depending on our intent— why we're interacting with the model in the first place. This distinction, it turns out, makes implementing inference a very nuanced and tricky task.
To see why this distinction matters, let's focus on two different use cases for inference. On the one hand, agentic workflows tend to be quite long-running tasks, so the primary measure of performance is the raw throughput that can be provided by an inference service. On the other hand, code completion workflows are very sensitive to latency, and throughput is typically relegated to a secondary concern. Even this distinction can be deceptive: high single-user performance may be essential in some settings, but in other contexts we might decide that the economics of processing many user requests at once outweighs pure speed. And even this isn’t the full story: if we’re even more performance- or memory-constrained, we can use techniques like quantization to trade accuracy for performance. This latency-throughput-accuracy tradeoff for inference matters hugely for user experience, and ultimately a good inference implementation will try to satisfy all of these criteria simultaneously, or at least provide the ability to choose between them without too much hassle.
But a truly excellent inference implementation needs to provide even more than this. As previously mentioned, inference acts as the carrier for all sorts of interesting workloads: evaluations, reinforcement learning, and even certain kinds of post training all need efficient inference to run successfully. Interestingly, this places an additional burden on an inference implementation: pure flexibility. Intuitively speaking, we wouldn't be able to keep up with the pace of exciting new ideas if we couldn't quickly implement any associated machinery inside our inference codebase. This flexibility even extends beyond pure AI workloads; we need to be able to flexibly implement new models and optimizations in our inference codebase to continually push AI research forward.
Lastly, an inference service also needs to provide several quality of life features in order to be viable. First, an inference service is a distributed system, and thus we need to keep a careful eye on error reporting, observability, and fault tolerance. Equally, a good inference service will be easy to quickly deploy across a wide range of hardware, and ideally flexible enough to adapt to different memory constraints and system configurations. Going further, an inference service should also provide a stable interface for users; no matter what optimizations or changes happen under the hood, a good inference service will make it easy for applications to make requests and receive responses. This is not to say that a good inference service shouldn’t provide some specialized APIs for certain use cases. Quite the opposite. But an inference service should ultimately be easy to use in a stable configuration.
Our solution to these challenges is Atlas, our inference codebase. Much like the Titan of Greek myth, Atlas handles the cumbersome task of running foundation model inference in a steadfast and reliable manner for many model architectures across multiple hardware platforms. Above all, Atlas presents a great deal of flexibility and performance for a wide range of workloads, both internally in the Factory and externally for our customers.
In the next two sections, we'll discuss Atlas's technical details. But before we move on, it's worth giving an overview of the philosophy behind Atlas. As we've mentioned, one of the key aspects behind a useful inference platform is flexibility, both in terms of the workloads and implementations. Atlas takes this idea one step further. In fact, our fundamental thesis is that in the context of inference, the ability to flexibly make changes is almost all that matters. Practically speaking, flexibility leads to rapidly compounding gains; over time, benefits that less flexibility might've yielded are outweighed by the improvements produced by flexibility. Of course, unbounded flexibility isn't a good idea either—structure is always needed at some point. But, by carefully balancing the tradeoffs between flexibility and structure, we end up with everything else we need for a good inference service almost for free. And, the compounding benefits aren't just limited to the inference service itself; instead, they propagate throughout the entire Model Factory, improving our ability to iterate quickly elsewhere.
How Atlas: producing compounding benefits through flexibility
We'll now turn our attention to how we've structured Atlas to produce compounding benefits through flexibility.
At a high level, Atlas is a library that provides components for inference workloads. These components can broadly be grouped into two categories: components that we've implemented ourselves and wrapped components from open-source inference libraries. Similarly to our pre-training codebase, Titan, we take the best of the open-source world and implement our own variants when existing solutions don't quite meet our needs. Each component can be viewed as an entity that is responsible for a single action. For example, we have several components that implement layer normalization, each tailored for a slightly different use case.
This design decision has several benefits. First, Atlas's composition-based design gives us the ability to easily swap out components depending on our particular requirements. For instance, transformer blocks typically utilize some form of layer normalization, which is a primary candidate for operator fusion. However, we may prefer to fuse the layer normalization with different operations on different platforms, depending on the underlying characteristics of the platform. By representing the transfer block as a component, we can easily swap out implementations without modifying the rest of the Atlas library. Moreover, by representing algorithms as components in this manner, we can easily implement inference for different model architectures. For instance, a multi-layer perceptron (MLP) is almost always placed after an attention block in a transformer, but the exact MLP used—or the exact attention mechanism used—varies across models. By abstracting both the MLP and the transformer block into components, we are able to define a high-level structure for our models and then specialize for each particular architecture.
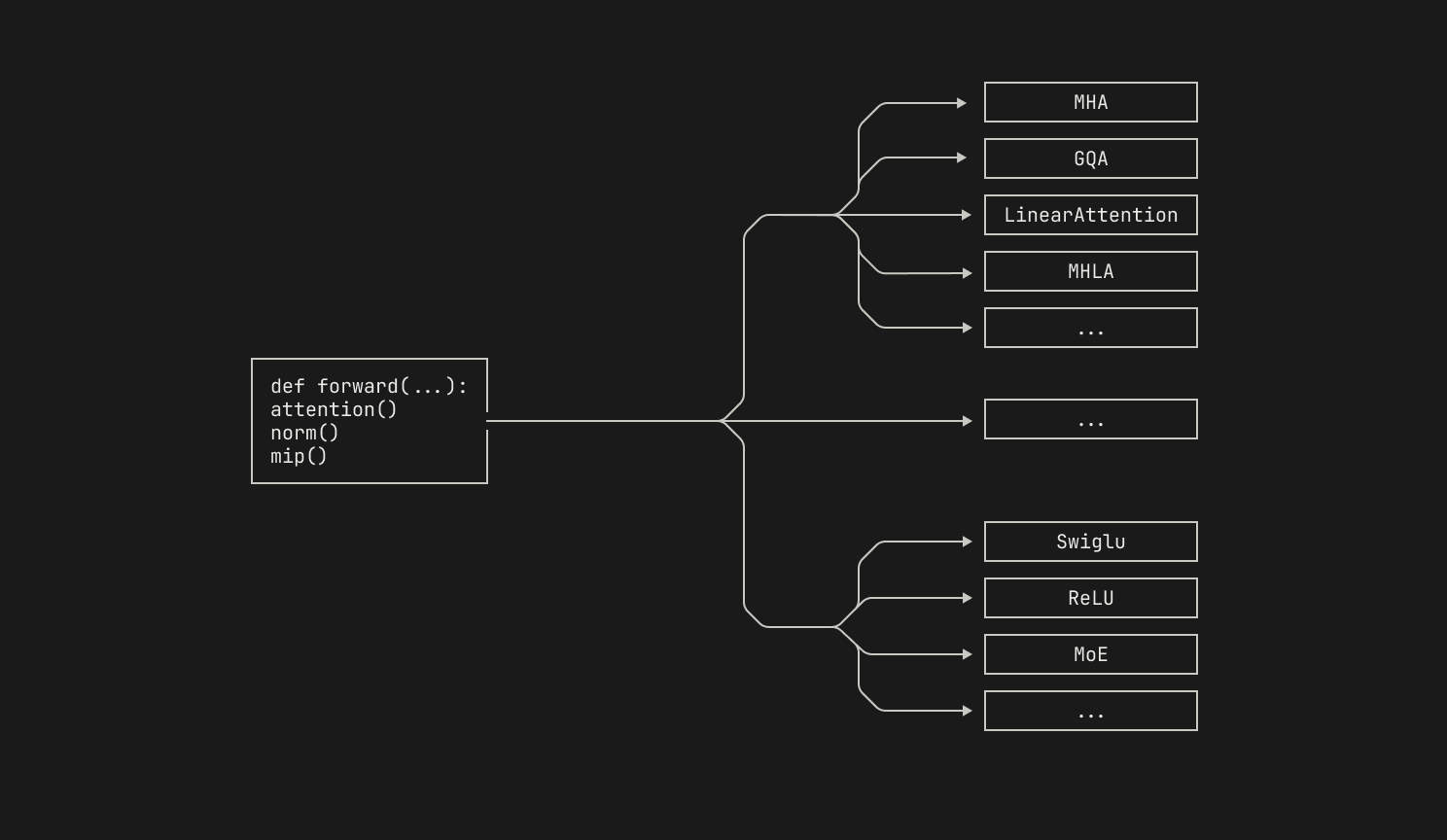
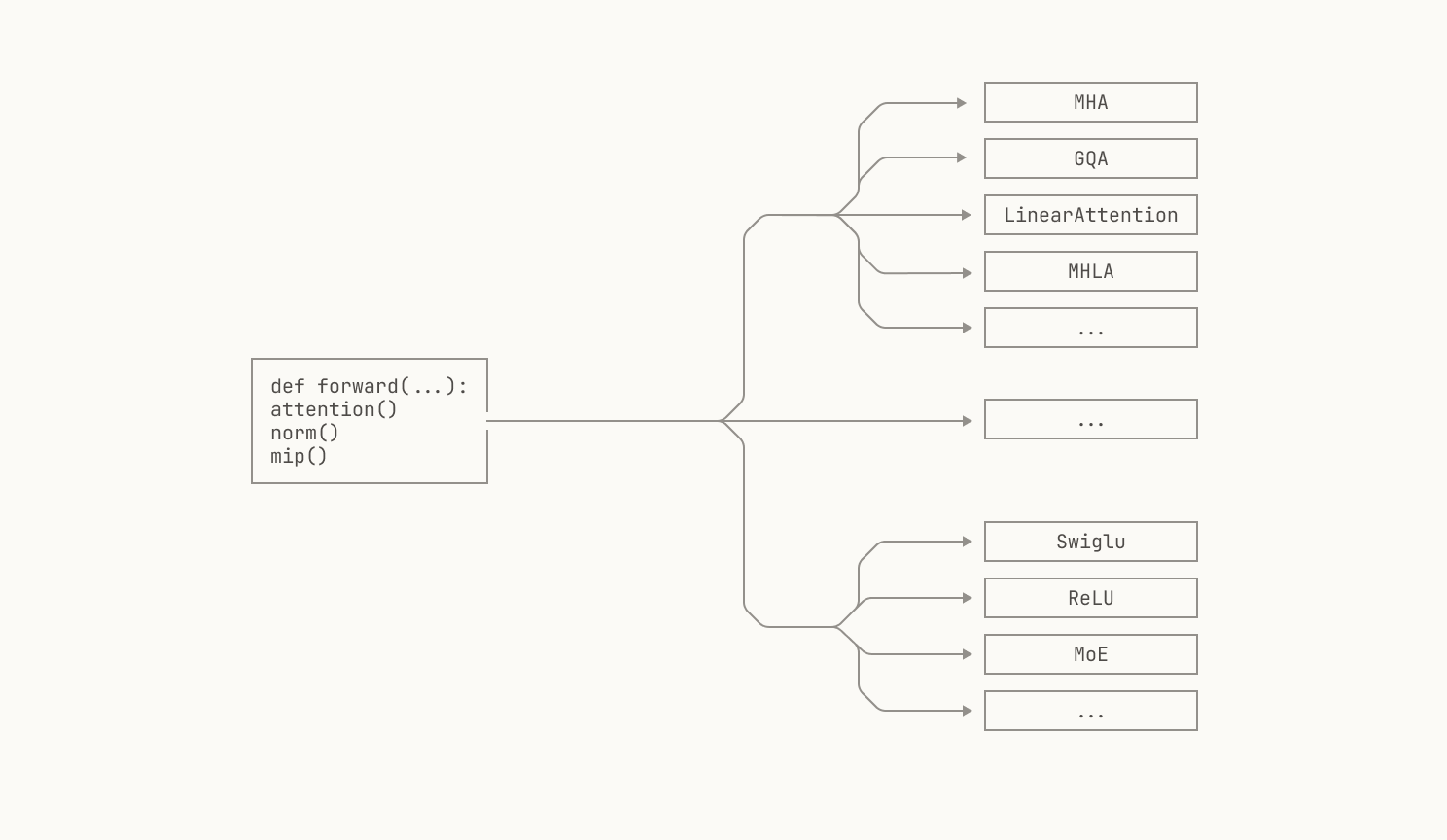
Moreover, Atlas's composition-based approach means that we can easily pull in various components from open-source inference libraries. Specifically, at the time of writing, Atlas wraps various components from vLLM, a popular open source inference codebase. This has substantial practical benefits for us. For instance, we don’t need to bother with reimplementing common functionality ourselves, like KV or prefix caching; we can simply utilize implementations of these components from the outside world directly in Atlas. Moreover, we’re big believers in open source at Poolside, and we contribute our own changes and fixes to these libraries when possible. This not only allows us to help sustain open source efforts, but it also reduces the divergence between upstream libraries and Atlas. In situations where Atlas diverges from upstream codebases, we can simply rebase our changes on top of any new releases.
Yet, one of the largest benefits to this approach is that we are able to define generic interfaces for various tasks, such as executing inference on a batch of requests. From a high-level perspective, the details of how the inference is actually executed are irrelevant; we can simply satisfy the specified interface. This makes making changes to other components—such as vLLM’s scheduler—much more tractable.
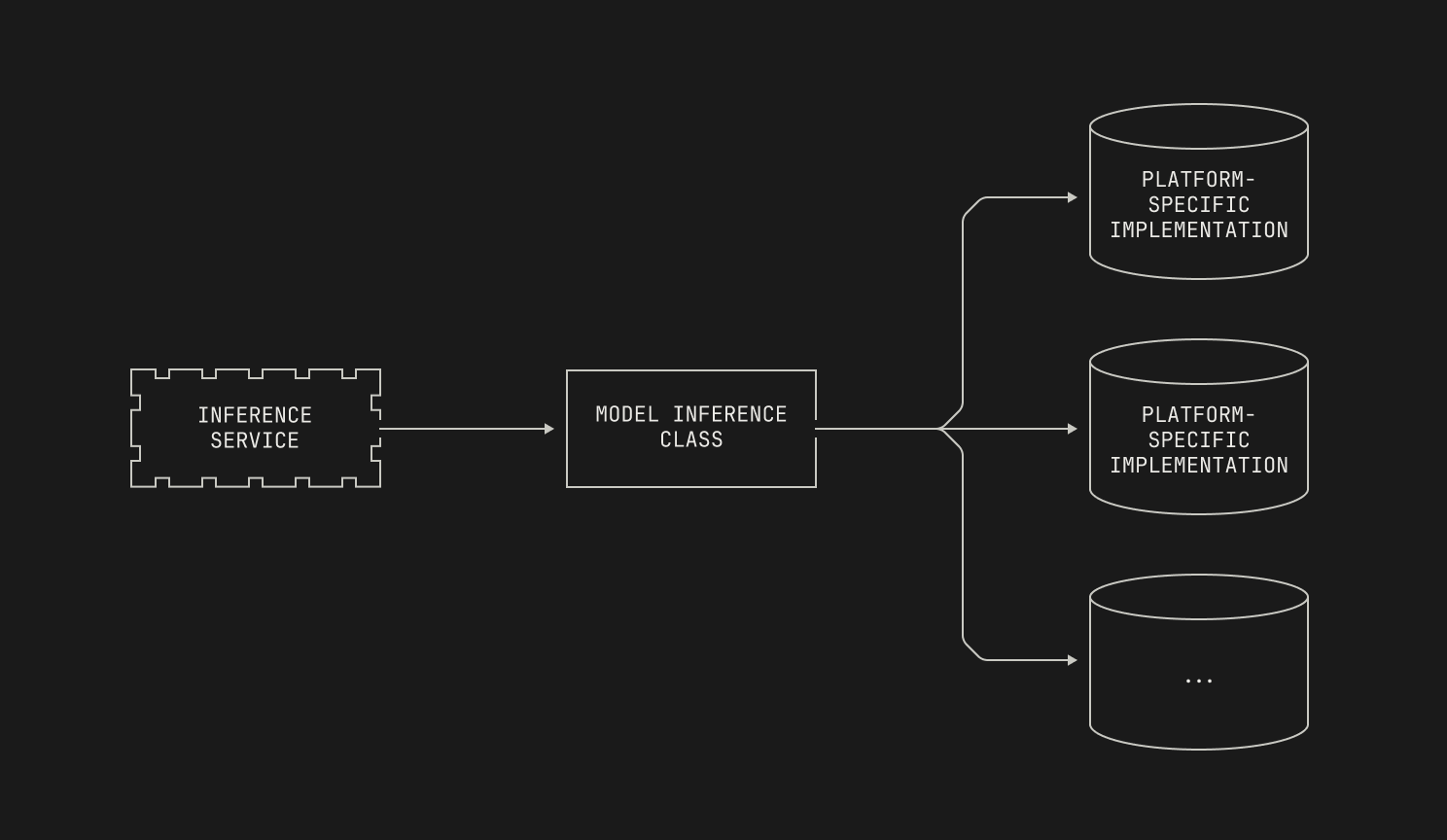
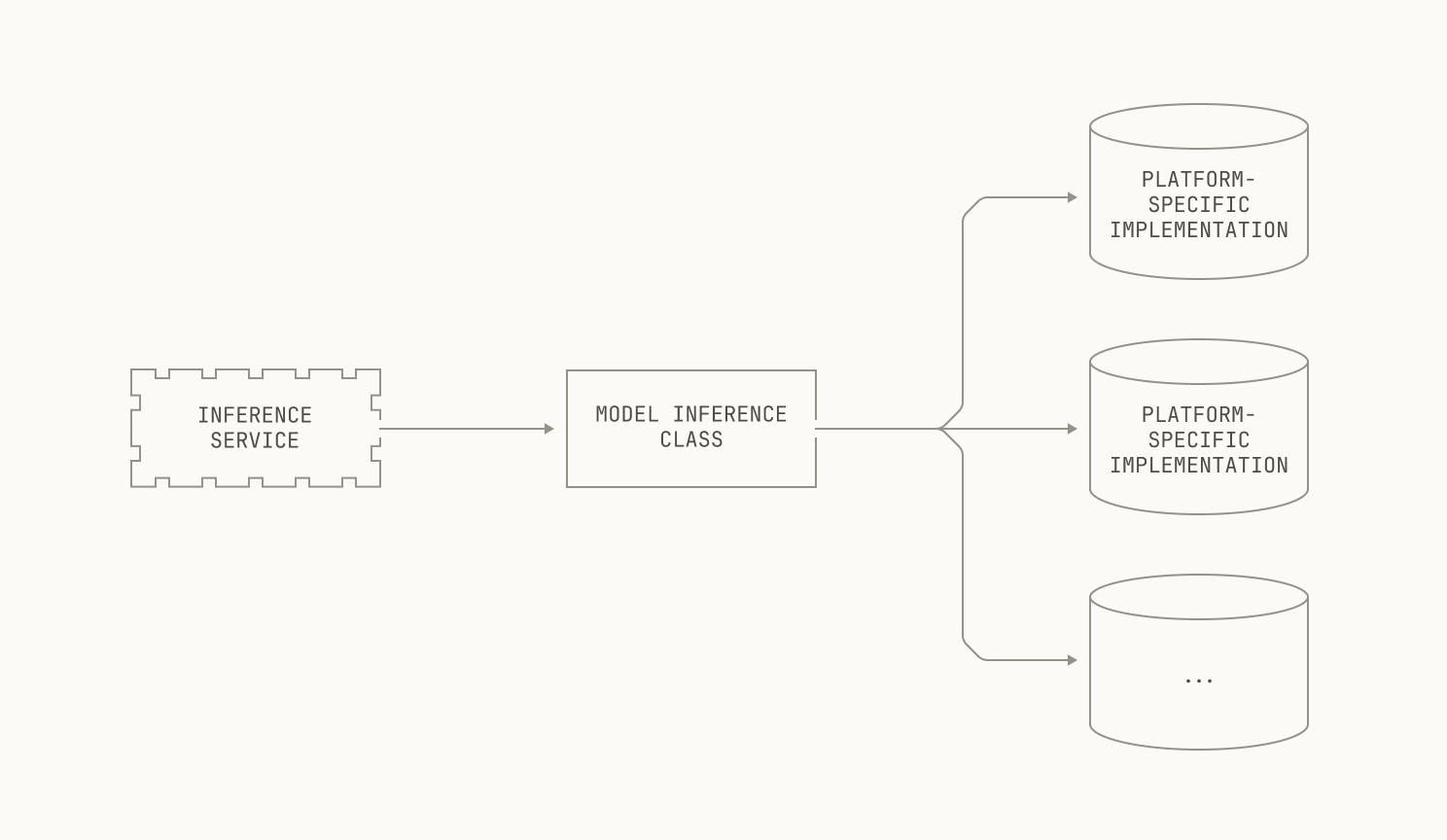
Now that we've discussed how Atlas is structured at a high level, we can dive into how Atlas works under the hood. As previously mentioned, Atlas provides generic interfaces for various tasks, enabling it to slot neatly into existing inference libraries. From an implementation perspective, these generic interfaces are backed by instantiations of each model. For instance, inference for our Malibu models runs through a generic interface into a class specialized for Malibu inference.
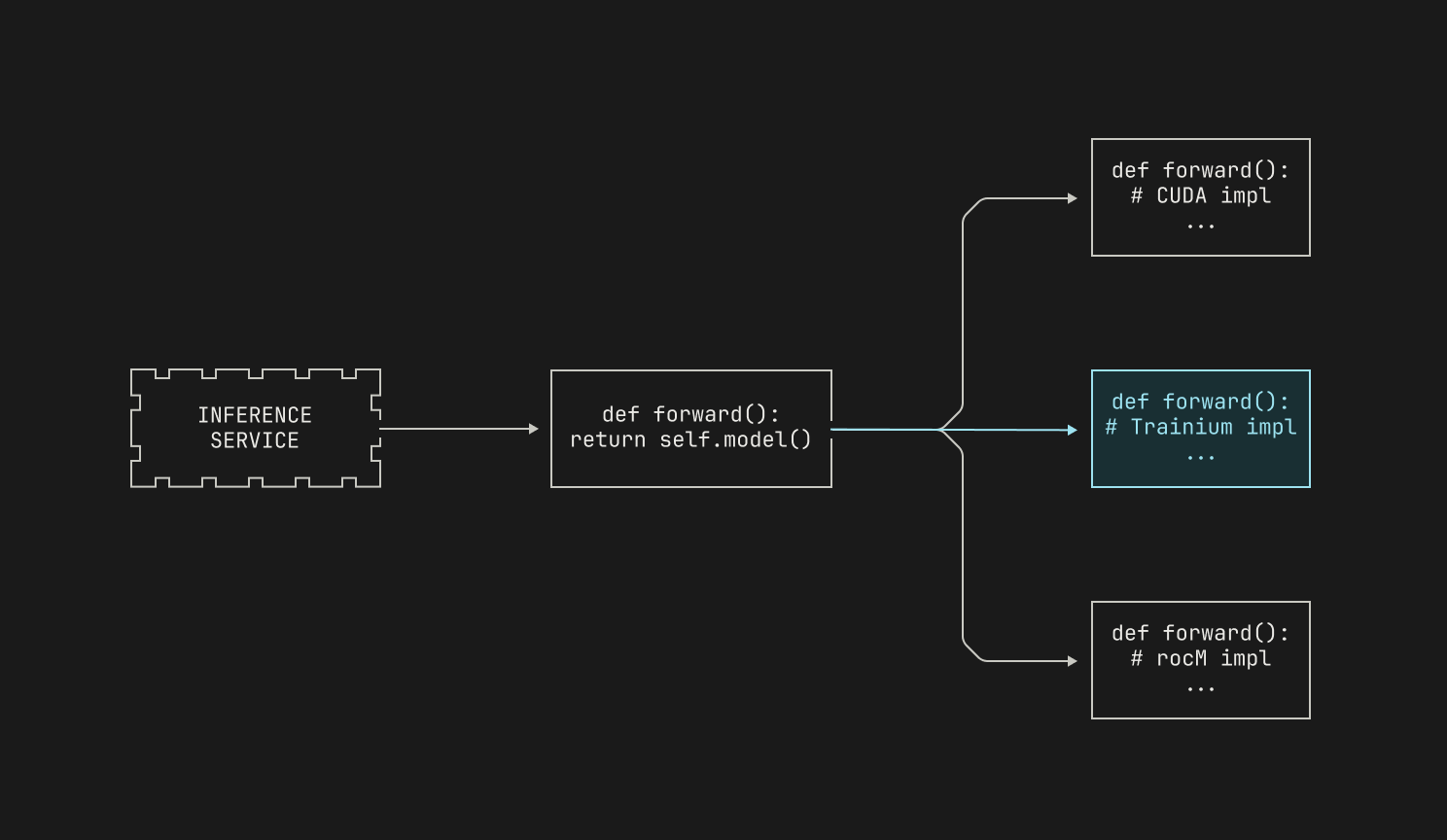
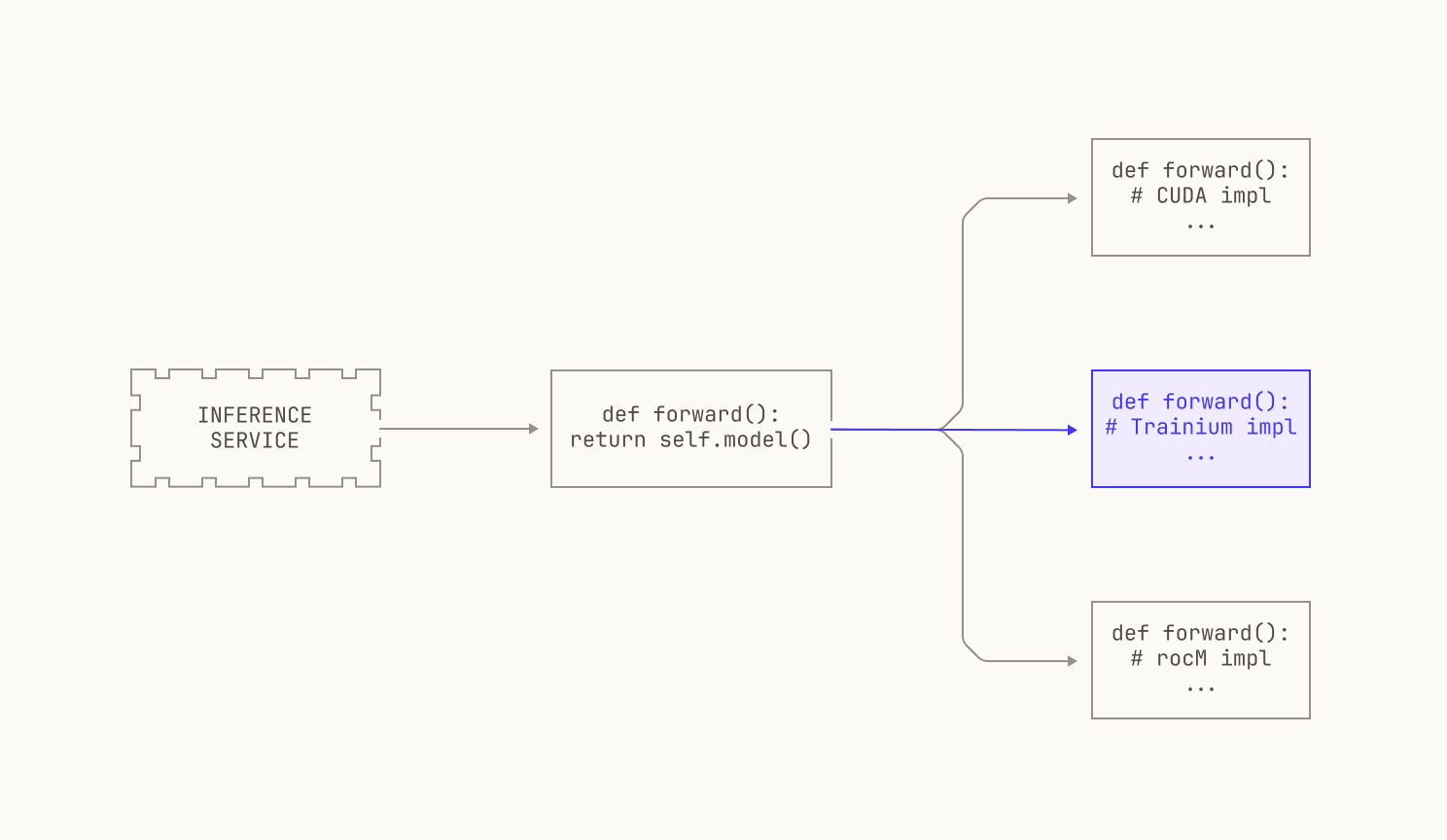
Although we’ve dedicated classes for each model, we stress that these classes are typically quite lightweight. Indeed, we typically simply define the various interfaces that a particular model needs to run inference, and then delegate the details to another external class that handles platform-specific details. We'll discuss how we actually handle different compute platforms in the next section, but we note that Atlas is flexible and runs on CUDA, ROCm and Trainium platforms at the time of writing. Still, for now we'll simply treat the underlying implementation as an opaque box, leading to the following picture.
Atlas also has the ability to use our pre-training codebase, Titan, as a dependency. In fact, Atlas inherits its model configuration class from Titan for compatibility reasons. We stress that using Titan as our sole source of inference would be unwise: after all, inference and training implementations are quite different, and some techniques that are useful in inference are unlikely to be useful for training. Put differently, a good training implementation of an operation will not necessarily be a good inference implementation of the same operation. Still, Titan allows us to compare Atlas's outputs against a known-working baseline, providing us with strong correctness guarantees for our inference implementations. This is especially important when we integrate new optimizations into Atlas, as it's easy to accidentally introduce regressions.
Atlas can be deployed in multiple ways. On the one hand, Atlas can be deployed on our worker nodes as part of our standard, Kubernetes-based deployment system. We’ll go into much more detail on how this system works in the “Deploying inference in the Factory” section, but we note that this particular deployment option makes incorporating Atlas with the rest of the Model Factory straightforward. On the other hand, Atlas can also be installed as a standalone package, allowing us to deploy Atlas in a variety of environments and setups. In fact, the ability to use Atlas locally has benefits outside of just developer workflows: it means that we can deploy Atlas in environments where our standard tooling is unavailable.
Where Atlas: optimizing inference across platforms
We now turn our attention to how we implement and optimize inference across different platforms. For the sake of this section, we'll discuss both how we handle inference on GPUs as well as Trainium. We stress that these are just examples; Atlas is flexible enough to allow us to deploy inference on all manner of compute platforms.
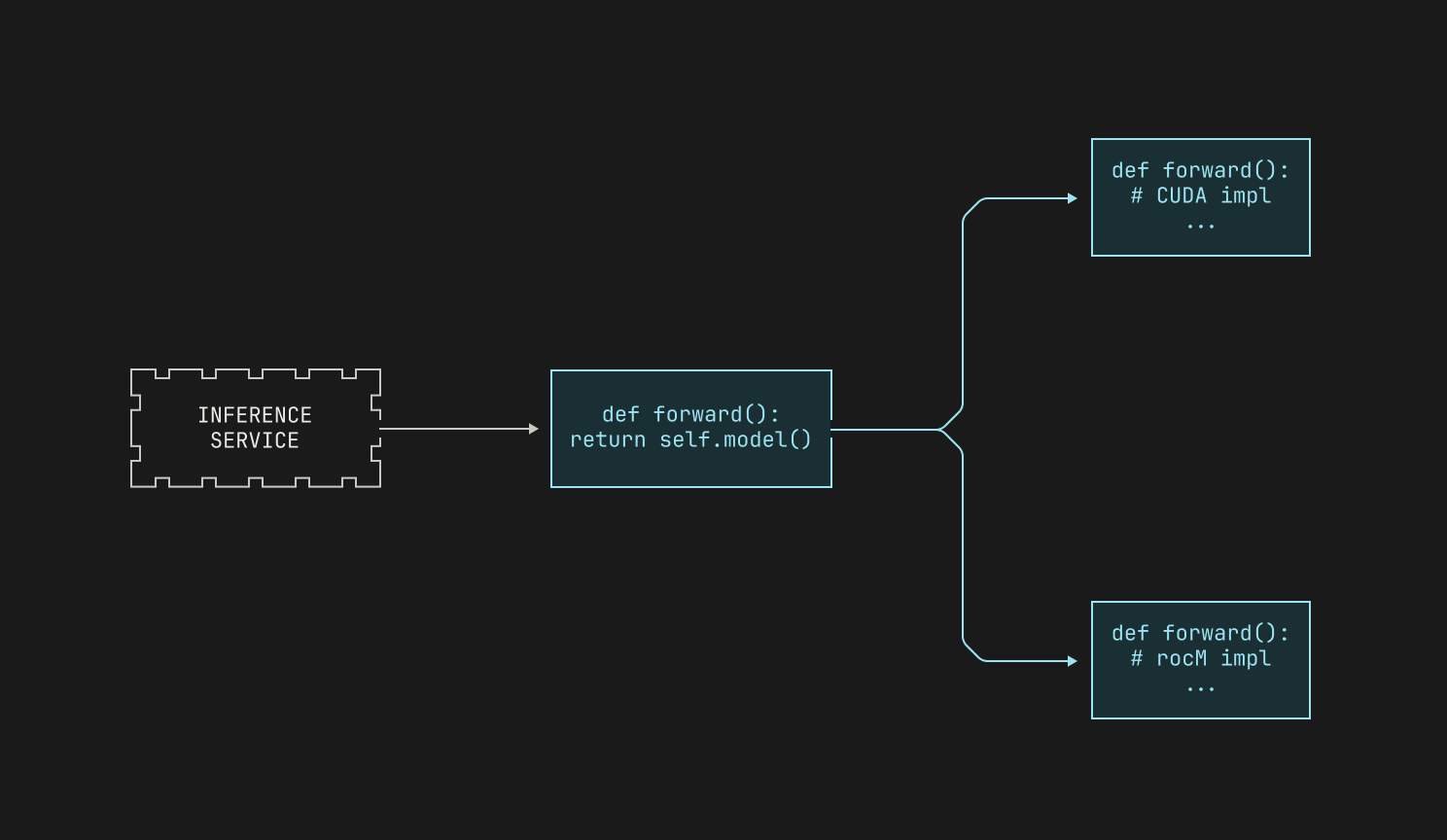
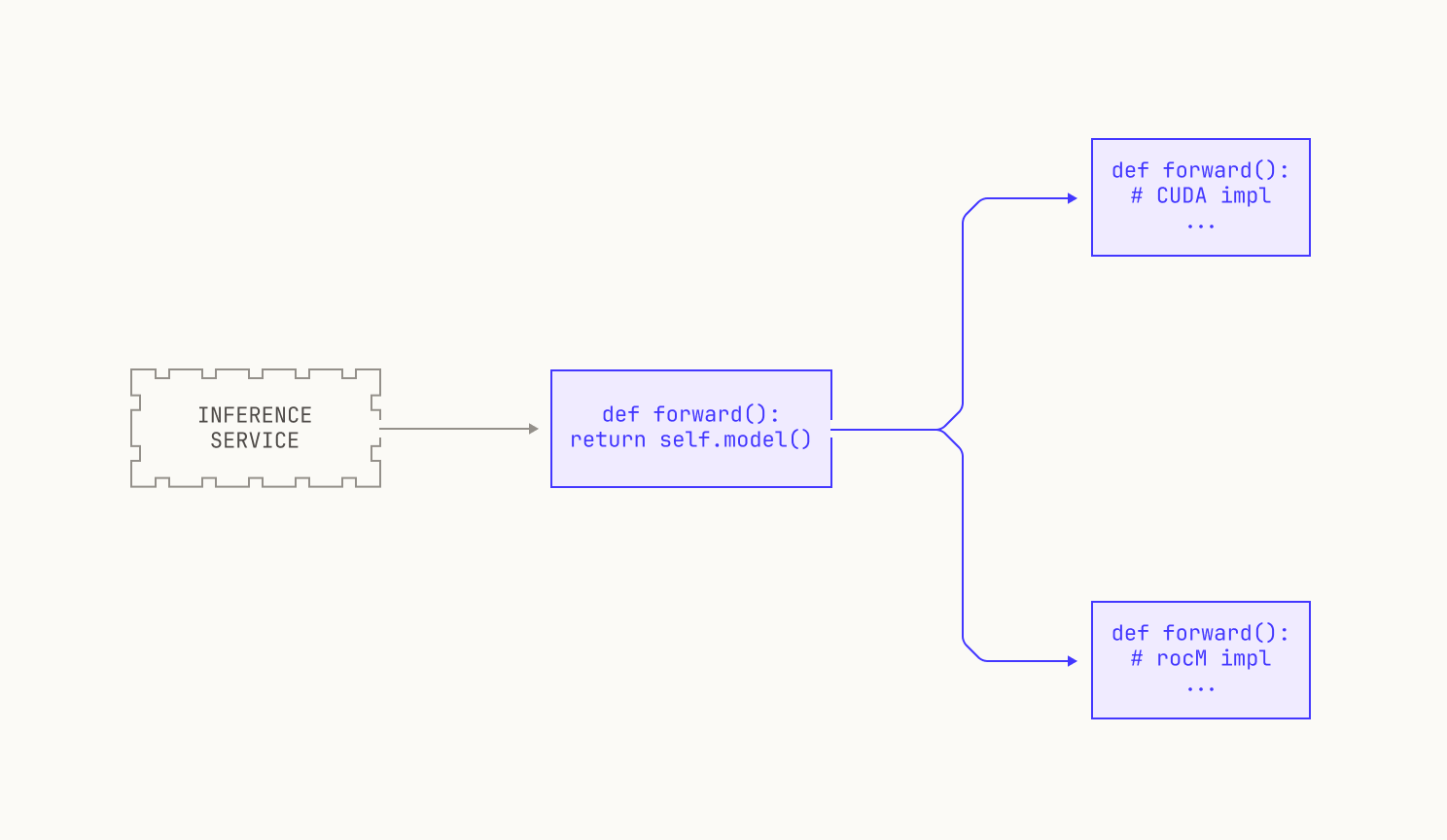
As mentioned in the previous section, we typically provide a wrapper class to provide inference for a particular model. One of the benefits of such a generic interface is that we can abstract away platform specific details. In fact, a similar approach can be found in vLLM, which represents models using so-called `ModelForCausalLM` classes. In order to add platform-specific capabilities to these classes, we simply subclass the wrapper class with platform-specific implementations, with each subclass handling all of the needed details for running inference on that particular platform. We then load the correct subclass at runtime, depending on the underlying hardware on which Atlas is deployed.
We now discuss how we implement inference on GPUs. Both CUDA and ROCm are well-supported in the open source world; there are many optimized kernels available in the wider world, and Torch provides a solid baseline for both platforms. However, there are many low-level optimizations and hardware capabilities that are rather uncommon in the open-source world; after all, new hardware comes out all the time, but fast kernels tend to take a while to appear. And even fast kernels in the outside world might not take full advantage of the capabilities offered by any particular platform. In order to take advantage of these, we regularly write our own kernels for the hardware platforms that we target, allowing us to live at—and even beyond—the frontier of inference performance. Given that we'll potentially have different kernels for each platform, we thus wrap our CUDA implementations and our ROCm implementations separately, leading to the following high level view.
Inference on Trainium is broadly similar to inference on GPUs, with a few notable differences. Briefly, Trainium accelerators follow a different design strategy to GPUs; put simply, Trainium contains relatively few, powerful cores, whereas a GPU typically consists of many, comparatively weaker, cores. Neither approach is superior; each approach has its merits and drawbacks. Still, the differences are substantial enough to mean that platform-specific implementations are needed to get the best out of each. Thankfully, this is the same as with our GPU approach, and thus we can simply produce another wrapper class to implement Trainium inference.
From a programming perspective there are other differences. Notably, Trainium executes workloads by first compiling a so-called compute graph into an executable, which is then reused across invocations. This has several benefits:a full view of the whole program is useful to the compiler, but the tradeoff is that control-flow decisions are typically made during compilation. This leads to straight-line programs when the code is executed on device, much like with CUDA and HIP graphs. This actually presents us with an opportunity: almost all control flow decisions in inference relate to whether we're running the initial processing, known as prefill or the subsequent token generation. As these stages have different bottlenecks, we can actually benefit from writing separate implementations for prefill and token generation. We further optimize this process by writing custom kernels in the NKI programming language. In total, all of these decisions contribute to state-of-the-art performance on Trainium for our models.
Although we optimize inference for each kind of device that we use, there are also other aspects to consider when writing a truly fast inference implementation. It is well known, for instance, that the overhead of a kernel launch can outweigh the time it takes to actually execute an on-device kernel. However, it is less well known that this behaviour is variable, especially from the perspective of a host CPU. In fact, there are many things that can lead to subpar inference performance, like incorrect NUMA affinities or incorrect garbage collection parameters. Given the prevalence of these issues, the inference team at Poolside spends a great deal of time profiling and optimizing for whole system performance, not just device-side performance.
Outside of kernel and CPU tuning, the inference team at Poolside also invests a large amount of time and effort into benchmarking high-level inference techniques for Atlas. Again, we stress that this work is broadly conditional, and there are few optimizations that will be beneficial in all cases. For example, prefix caching really shines in code completion scenarios, as several requests are likely to share the same prefix. However, prefix caching also requires additional memory management compared to pure KV caching, and thus prefix caching may not always be appropriate. Given certain optimizations are only useful conditionally, we carefully weigh every new addition or change to Atlas to ensure that the overall change is, in fact, positive.
Another crucial part of implementing inference is maintaining correctness. In fact, although we judiciously use unit and integration testing throughout the Model Factory, Atlas takes extra steps to guard against potential regressions. Practically speaking, we impose a higher testing burden on Atlas compared to other projects for two reasons. First, Atlas acts as the inference engine for our customer workloads, and we consider bugs in this area to be unacceptable. Second, because inference serves a carrier for so many other workloads in the Factory, the consequence of even a small bug can be significant. We stress that these consequences reach beyond costing us time and money: a bug may also influence the outcomes of our experiments, potentially leading us to incorrect conclusions. In order to prevent regressions at scale, Atlas takes a heavy handed approach to testing. In particular, Atlas contains several end-to-end tests for entire subsystems of the Model Factory: we spin up entire job deployments as part of our continuous integration (CI) workflows and meticulously compare any results against known good values. Moreover, we also deploy different CI workflows for each hardware platform that we support, allowing us to ensure that inference on one platform is never silently broken by changes for another. This process, admittedly, requires some nuance to handle properly, but any complexities here are far outweighed by the confidence that this process gives us to make changes.
Before we move on to how we deploy inference in practice, it’s worth discussing what implementation flexibility gives us. First, we are able to decouple the Model Factory's inference needs from the underlying hardware: instead of exclusively needing GPUs, we are able to offload certain inference tasks onto other types of hardware. Moreover, Atlas's flexibility also means that we can easily adapt to new customer environments and workloads; we simply need to adapt our existing inference code to the new platform, and Atlas's other facilities take care of the rest.
When Atlas: deploying inference in the Factory
Now that we know about how we actually implement inference at Poolside, we can begin to discuss how we typically use inference as part of the Model Factory.
It is no exaggeration to say that inference powers almost everything inside—and everyone who uses—the Model Factory. First, inference provides us with the ability to quickly evaluate models against a wide range of benchmarks, giving us the ability to easily judge how well models perform both during and after training. We stress that this is a crucial piece of the Model Factory; without the ability to objectively judge our experiments, we wouldn't be able to accurately interpret any results. Moreover, inference allows us to easily generate new synthetic datasets, conduct post-training at scale, and run large-scale reinforcement learning workflows. Put simply, without an easy and fast way to run inference, the Model Factory would be far less productive.
We've already covered how we run inference quickly inside the Factory in the previous section, so now we'll go into how we run inference easily. Broadly speaking, running inference easily requires doing three things well. On the one hand, we need a way of managing model deployments and our compute cluster: after all, inference deployments are compute jobs, and so we need to balance them against the rest of the jobs in the Factory. On the other hand, we also need to make it easy to invoke inference from other pieces of the Model Factory, as otherwise we simply won’t be able to make the best use of our resources.
To explain how the whole system works, we'll need to pull back the curtain on how we manage job deployment inside the Model Factory. After all, it's not like we only run inference on our cluster; we also have to balance our ability to execute any workload that requires GPUs. In other words, we need to take a holistic view about how we schedule jobs.
Scheduling jobs at scale is a complicated task; and not all compute jobs are equally important. For example, a large-scale training run shouldn't be obstructed by many small-scale synthetic data generation tasks; training is clearly more important. In other words, we need to be able to schedule jobs based on their priority. Moreover, not all compute jobs can reasonably be marked as "finished." For instance, we might deploy an internal model for vibe checking on our cluster, but it's not obvious when such a job should be marked as completed, at least from an automatic perspective. It's also not clear that all compute jobs should require a fixed number of GPUs ahead of time; vibe checking might only ever need a few GPUs, but there are some cases where we just want a job to finish as quickly as possible. This means that we need to somehow encode the fact that the number of GPUs assigned to a task may change dynamically over time. And we have to be careful to make sure that our GPU nodes don't become fragmented: it's easy to inadvertently end up in a scenario where we don't have any nodes with enough free GPUs to schedule anything other than very small jobs.
In order to implement all of this functionality, we use a two-tiered approach. First, we use Kubernetes to manage the underlying nodes, allowing us to take advantage of its abilities to automatically (and scalably) deploy containerized workloads across our 10K GPU cluster. However, we don't just use Kubernetes as-is; we also make use of a third-party scheduler, known as Volcano. Volcano is an open source, widely-used batch scheduling system for Kubernetes that allows for more advanced use cases. For instance, Volcano supports assigning jobs to nodes via binpacking, reducing job fragmentation across our cluster. Volcano also gives us powerful scheduling primitives, such as all-or-nothing scheduling and fair sharing. Moreover,
Volcano also gives us the ability to prioritize jobs via multiple priority queues, allowing us to easily prioritize certain compute jobs. By using Volcano, Kubernetes and Dagster together, we are able to realize more advanced functionality, too; for instance, we can mark certain jobs as static (i.e. requiring a precise number of GPUs) or as dynamic (i.e. able to scale up to a maximum number of GPUs). We also have advanced lifetime primitives. For instance, we use Dagster to automatically update a deployment's TTL whenever the deployment is used, preventing certain jobs from expiring too soon, certain jobs can be marked as evictable, allowing for pre-emption in the case that a more pressing compute job needs to be scheduled. Our scheduling system also supports backfill, preventing very small jobs from being blocked by larger, less ephemeral tasks.
With the details of scheduling out of the way, we can now discuss how we schedule inference deployments. The answer is simple: we schedule inference deployments in the same way that we schedule any other compute job. Intuitively speaking, this is a corollary of how the abstractions in the Model Factory stack together, acting as more than the sum of their parts. In the case of managing infrastructure for inference, we can simply reuse the existing scheduling components from the rest of the Model Factory. Specifically, we can schedule inference workloads on our GPU nodes by submitting jobs in the same way that we would for any other workload, and our scheduler handles the rest. Moreover, we aren't tied to any particular underlying hardware; Atlas is fully containerized, and thus we can easily deploy Atlas on any compatible node. Visually speaking, this looks as follows.
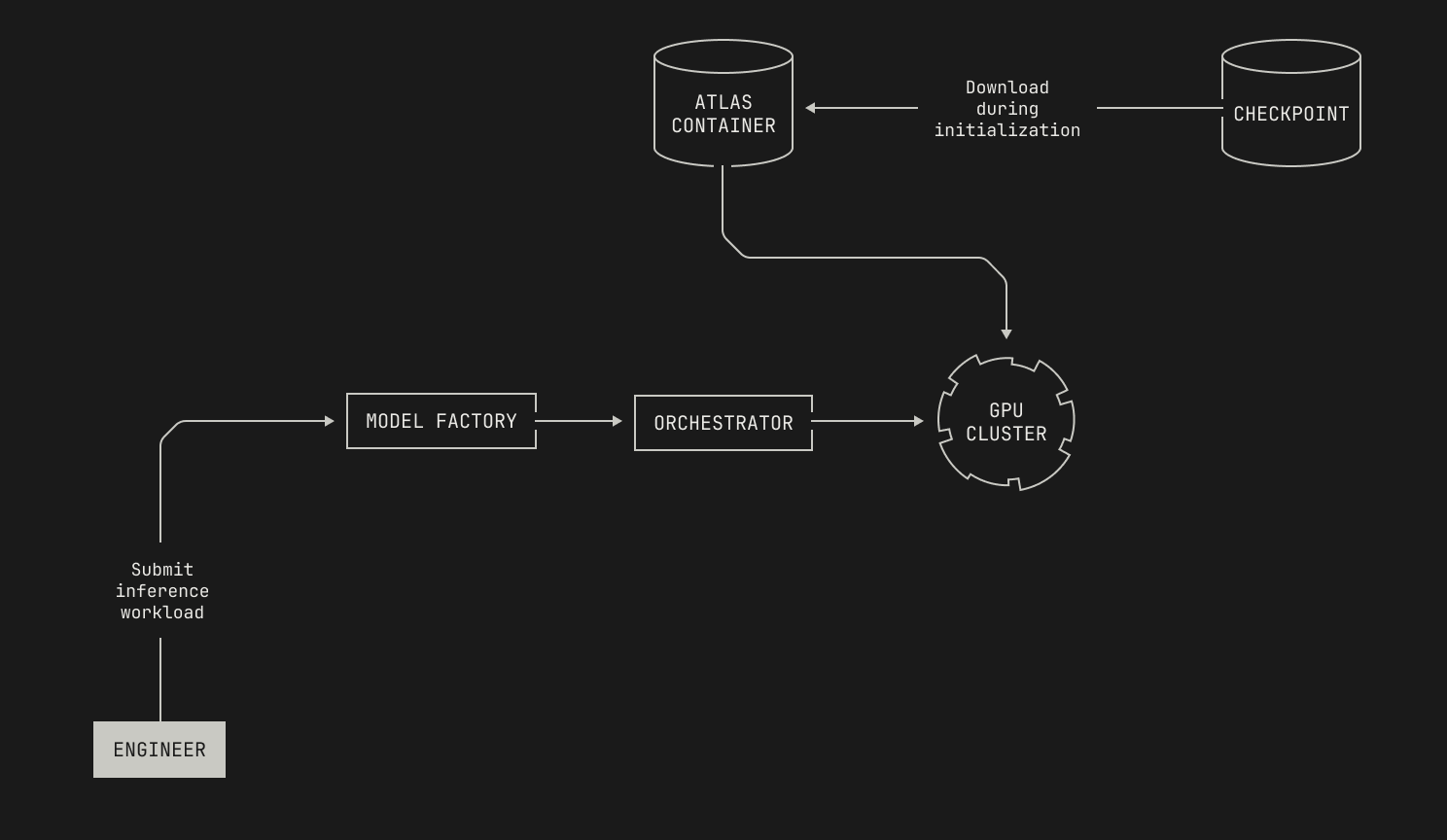
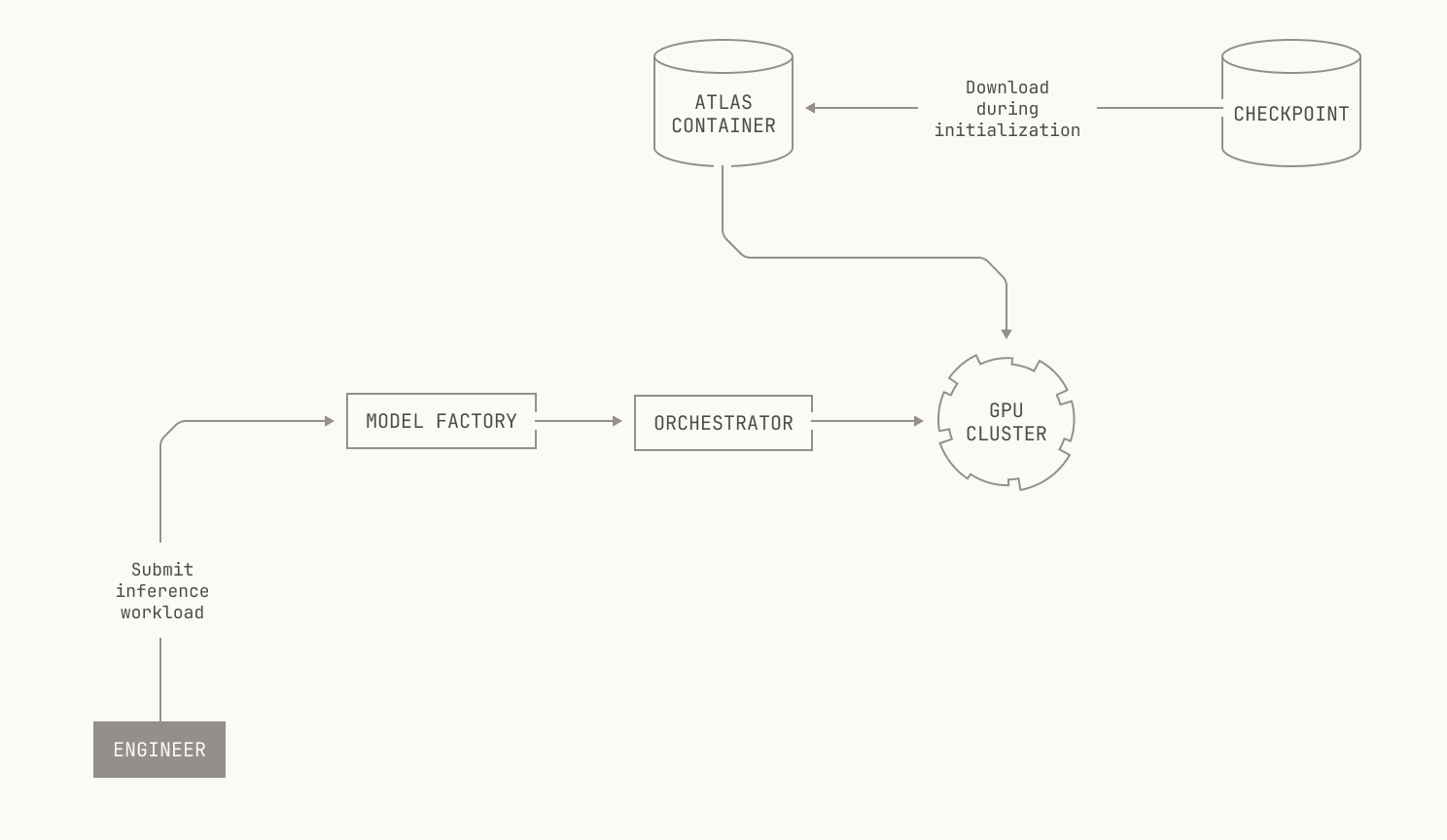
Now that we know how inference deployments are scheduled, we need to decide how we'll actually deploy and serve inference. In fact, this is also simple: we simply need to specify a checkpoint and some workload details. In particular, we can deploy an Atlas container that will automatically download the specified checkpoint during initialization. In practice, we can specify the checkpoint to use in one of three ways. In situations where we have a preexisting checkpoint, we can simply pass the checkpoint's identifier into the container as part of the job's launch configuration. However, we might want to launch a particular workflow before a checkpoint even exists; for instance, when we run evaluations during training, we won't know the identifier of the checkpoint until it's been produced. Thankfully, Dagster supports such combined workflows, allowing us to first materialize a checkpoint asset and then automatically pass the identifier into any subsequent deployments. Lastly, we also have support for directly transferring model weights from GPUs that are used for training to GPUs that are used for inference, referred to as GPU<>GPU weight transfer. We'll discuss the details of the last approach in a forthcoming post, but for now it's worth knowing that this also slots neatly into the rest of the Model Factory's abstractions.
Once the deployment has been made, serving inference is comparatively easy. In particular, Poolside has an internal inference API that handles the routing and processing of all inference requests inside the Model Factory. Notably, our internal inference API manages various technical details for us, such as allowing for inference replicas, and intelligent request routing. Our internal API also provides various additional features, such as the ability to retrieve internal logs and upstream Dagster information.
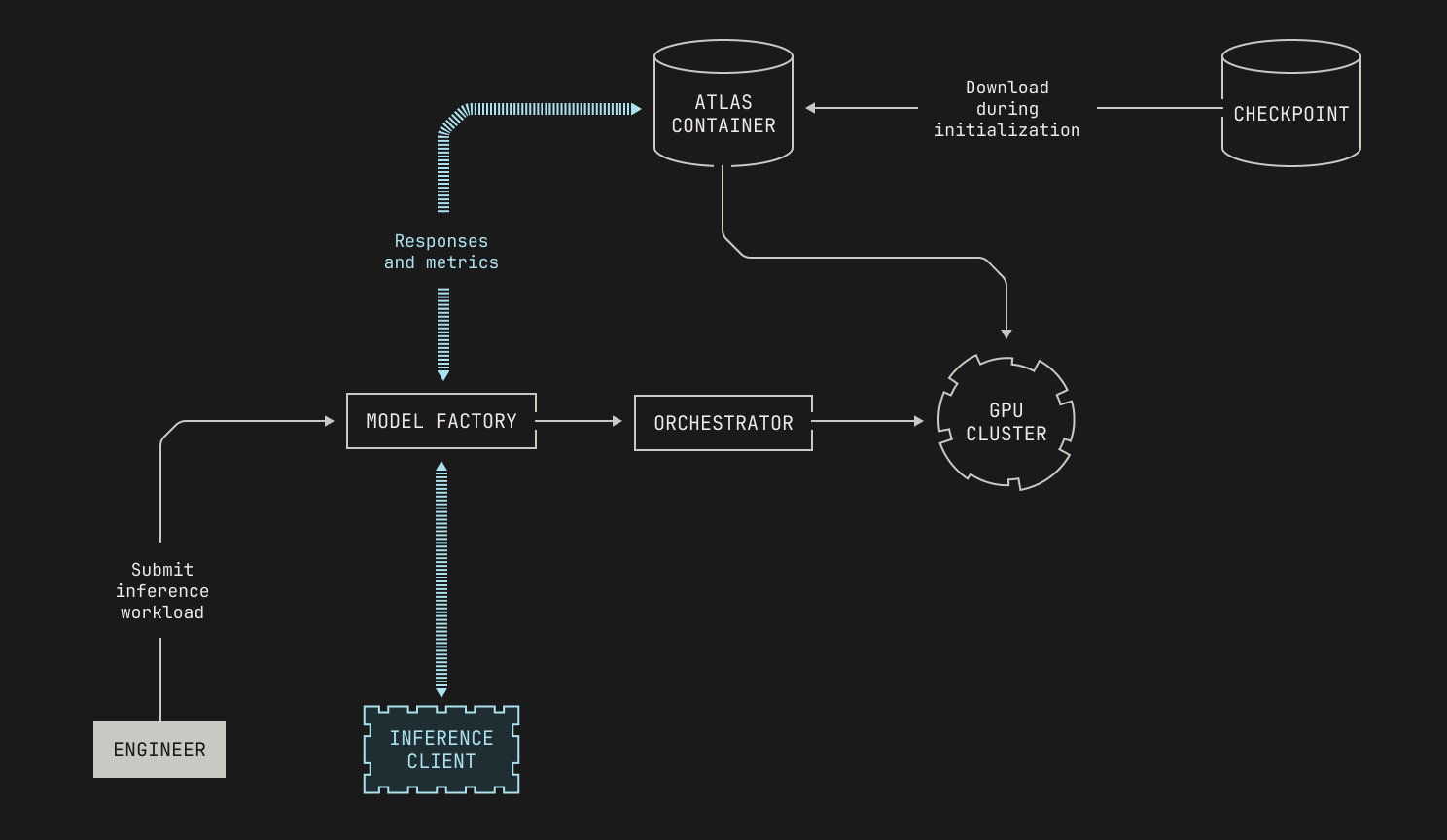
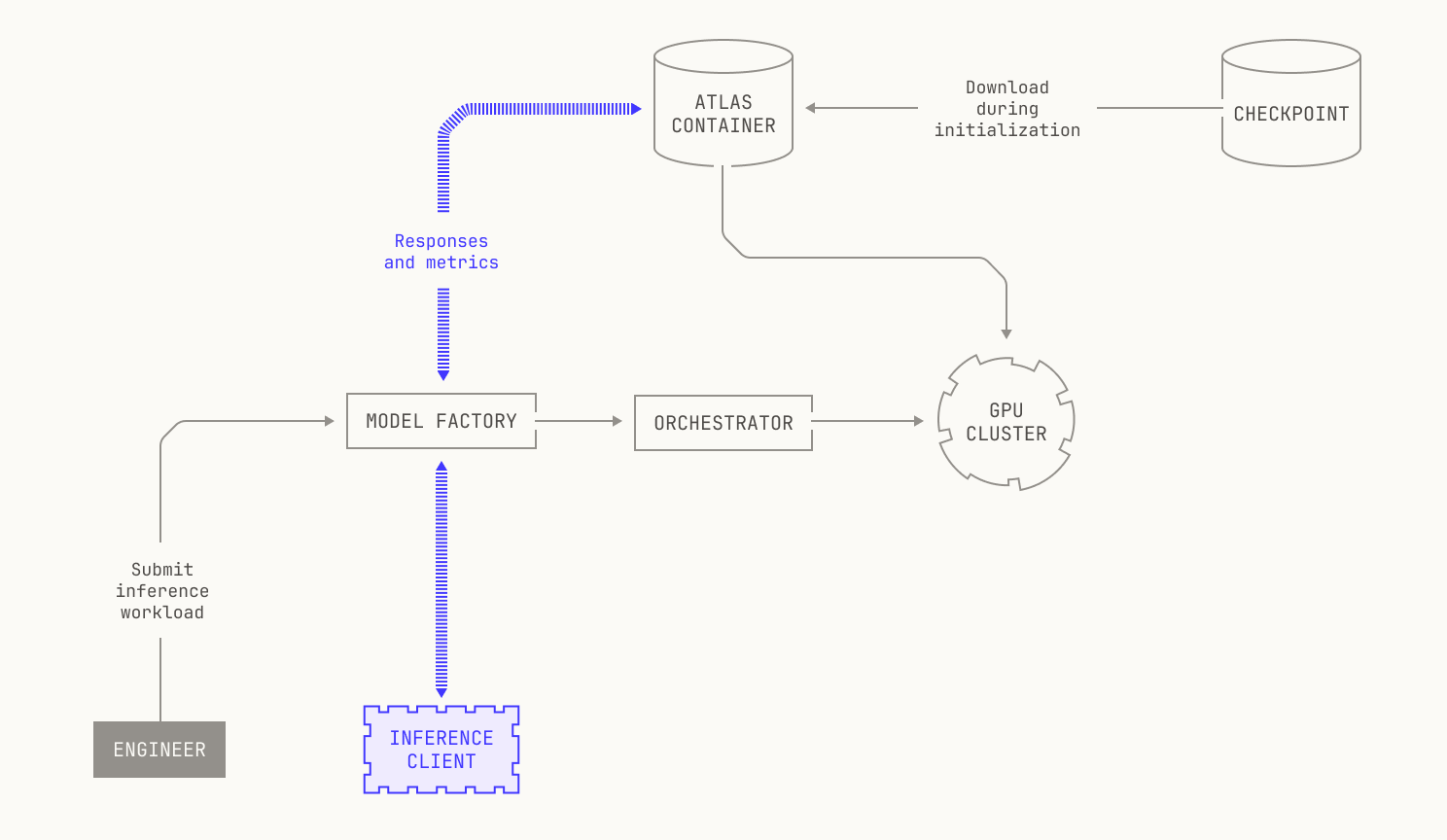
And that's all! Now that all of the details are out of the way, we can simply specify the deployment that we want to use in our upstream code, and we're ready to run whatever workflows we choose. Everything just works automatically. Of course, the exact way that each workload interacts with the underlying inference service—in terms of the usage patterns and so on—depends on the particular task that we're executing. Yet, all of this is easily abstracted away using the Factory.
Before we move on to a particular use case of inference, it's worth stressing how much inference (and the solid infrastructure around it) helps us to power the Factory. We would hardly be able to run automatic evaluations if we needed to manually deploy models; we simply wouldn't be able to keep up without babysitting our infrastructure constantly. However, making models easy to deploy by hand also allows us to quickly vibe check new models for capabilities and run ad-hoc experiments in a low friction fashion. These benefits only compound in the case of large-scale training and reinforcement learning workflows; in fact, it's hard to imagine a world in which we could run our current workloads without automatic and easy inference deployments.
Evaluations
Before we wrap up this post, we'll discuss how we use Atlas and the Model Factory to implement automatic evaluations at scale.
As a brief reminder, evaluations are a mechanism for judging how well a model has learned to perform certain tasks. Specifically, evaluations allow us to judge how well a model performs on useful downstream tasks; and this is how evaluations are typically used in the wider world. But at Poolside, we also use evaluations in another way: we deploy evaluations very early during model training to tease out specific, foundational capabilities that we expect will help on downstream performance, such as mathematical ability or natural language understanding. Intuitively speaking, we would like models to exhibit these skills early in training because they’re prerequisites for good software engineering performance: obtaining and solidifying these skills early in training will lead to a model that performs better on the tasks that we care about. In order to get a strong signal about how our models perform on these tasks, we need to run evaluations frequently during training, and this is where our ability to scale really matters. Indeed, we recall from our previous posts that we run thousands of data and architectural experiments; if we couldn’t accurately and quickly evaluate these experiments, they would bottleneck our ability to continue experimenting and training models.
Although we make extensive use of evaluations, it’s worth stressing that no evaluation is perfect. Intelligence is multifaceted, and no single test can accurately gauge intelligence, artificial or otherwise. What's more, a model's quality is somewhat subjective, and building a model that people enjoy using is the product of far more than just good benchmark results. Yet, running varied and representative evaluations regularly can still help us to understand how our models perform and evolve during training and experimentation. Choosing good evaluations is as much of an art as it is a science—but we’ll save that discussion for another time. Instead, we'll focus on how we run and implement evaluations as part of the Model Factory.
The first question we have is how we should implement the evaluations themselves. Let's imagine that we're only considering internal-only evaluations (i.e. there's no existing external implementation). What choices do we have here? On the one hand, we could implement the evaluations as stand-alone scripts that simply execute the evaluation as-is and push the results to some dashboard. But this approach is hardly rigorous; after all, individual, unversioned scripts have a tendency to become unruly. On the other hand, we could implement each evaluation as a separate piece of the Model Factory, and benefit from the abstractions that we’ve already built in the Factory. Anecdotally speaking, we’ve noticed that the benefits of reusing these abstractions goes beyond just code reuse. Indeed, good abstractions tend to lead to cleaner code, and we’ve found that the Model Factory makes it much easier to isolate exactly how a particular evaluation operates. And, we’re able to take advantage of components that we’ve already optimized heavily, such as our inference service.
In fact, we’ll go one step further and re-implement external evaluations in terms of the Model Factory, too. This may be contentious, but the benefits are clear. Indeed, there's no guarantee that external evaluations would slot into the Factory; they may be written in unusual programming languages, or simply not support wide-scale deployment. In fact, engineers at Poolside regularly rewrite existing evaluations into native pieces of the Model Factory. Put bluntly, we express all the evaluations that we run as assets in the Model Factory. This has multiple benefits. Representing evaluations as assets means that we can more easily reinvoke evaluations across multiple experiments; just like the rest of the Factory, evaluations become a reusable component in their own right. Additionally, treating evaluations as assets in the Model Factory means that we can take advantage of the wider machinery of the Factory for advanced workflows.
Let's zoom in on this last point and consider the following situation. Suppose that we have a large evaluations framework that doesn't slot into the Model Factory, and we want to use this framework to evaluate a checkpoint. First, a large evaluations framework will likely require many GPUs to run evaluations on a checkpoint. As this framework isn't compatible with the Model Factory's scheduler, we would need to manually allocate GPUs and then execute the evaluations, possibly by hand. Even if only one evaluation actually needs all of these GPUs, it doesn't matter: we've already manually allocated them, and so they can't be reused for anything else. What's more, we need to manually execute the framework ourselves against a given checkpoint; even if we added some form of automation here, we're still moving backwards compared to what we can get from using the abstractions in the Model Factory.
Now let's see how the Model Factory can help us. First, we'll decompose the evaluations framework into individual, native Model Factory assets. We can now treat each evaluation as its own individually schedulable job; this means that we will not need to occupy a large number of GPUs at once, and the orchestrator can handle the actual scheduling for us. This approach has another benefit, too: because evaluations are independently schedulable, we can actually run the same evaluation multiple times in parallel against different checkpoints. This is only possible at our scale because of the abstractions inside of the Model Factory; instead of needing to wake up in the middle of the night to run evaluations, the Model Factory handles it all for us, and the results are ready for us in the morning. This leads to the following high level workflow:
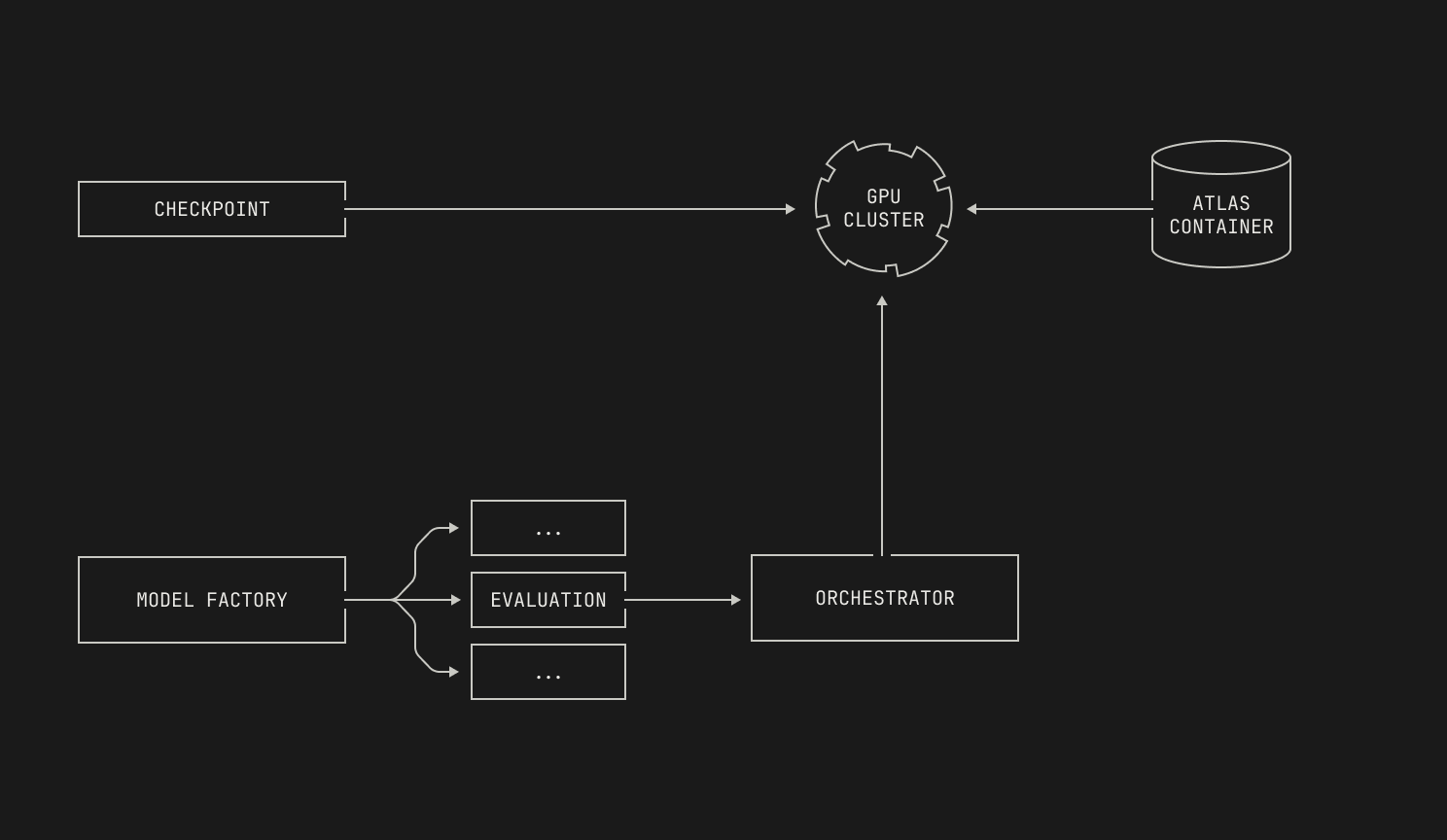
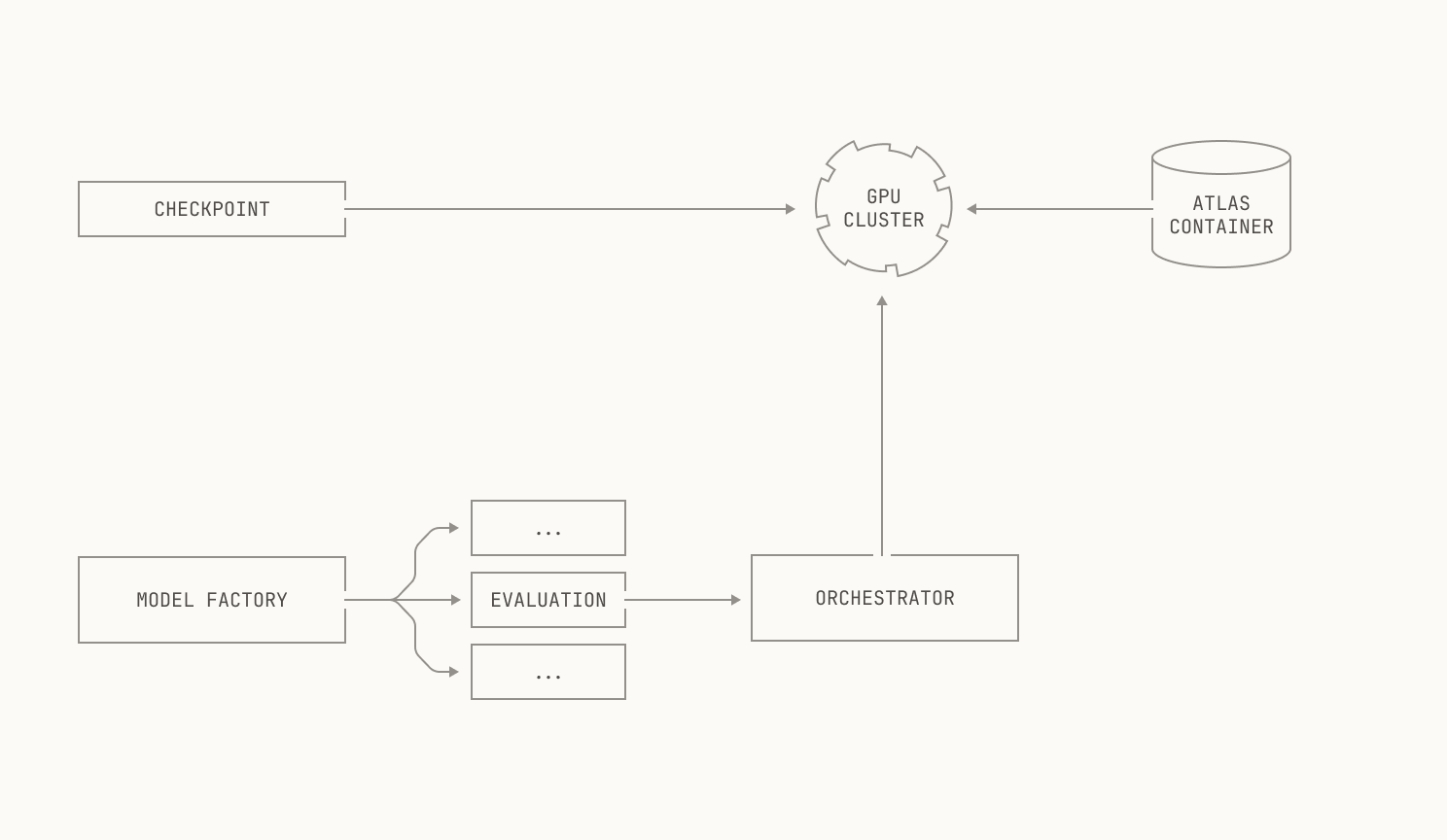
Let’s unpack the “Evaluation” box. As mentioned earlier, our evaluations require that we run inference on a particular checkpoint, and thus we’ll need to spin up an inference deployment. Moreover, our evaluations are broad, and some require code execution; we’ll need to deploy that too. We’ll also need a way to read sample datasets from Apache Iceberg tables, along with a handful of other auxiliary primitives like logging. Notably, none of these components are implemented just for evaluations: we’re simply reusing systems that we’ve already built for the Model Factory. Visually speaking, this looks like the following diagram:
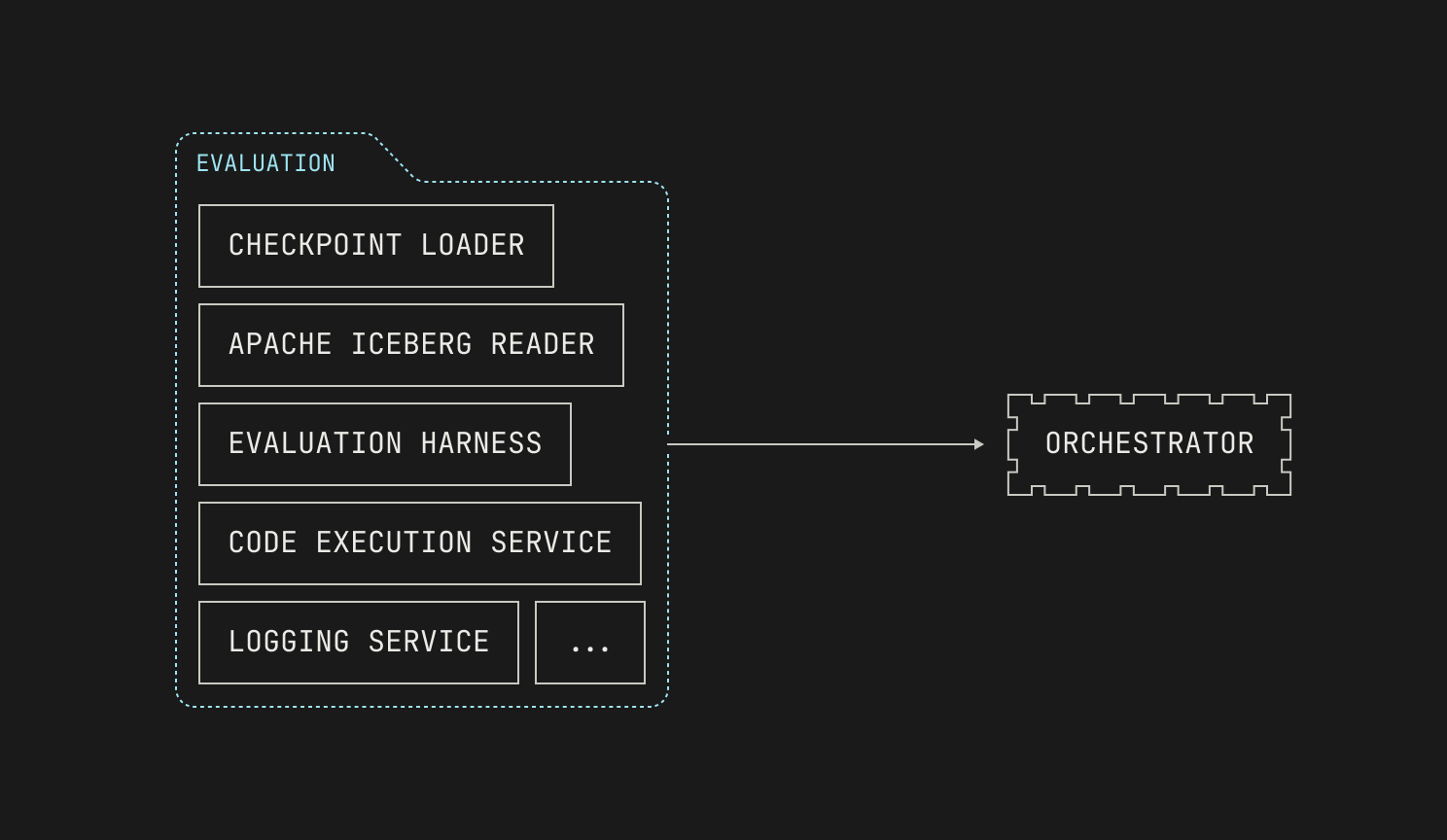
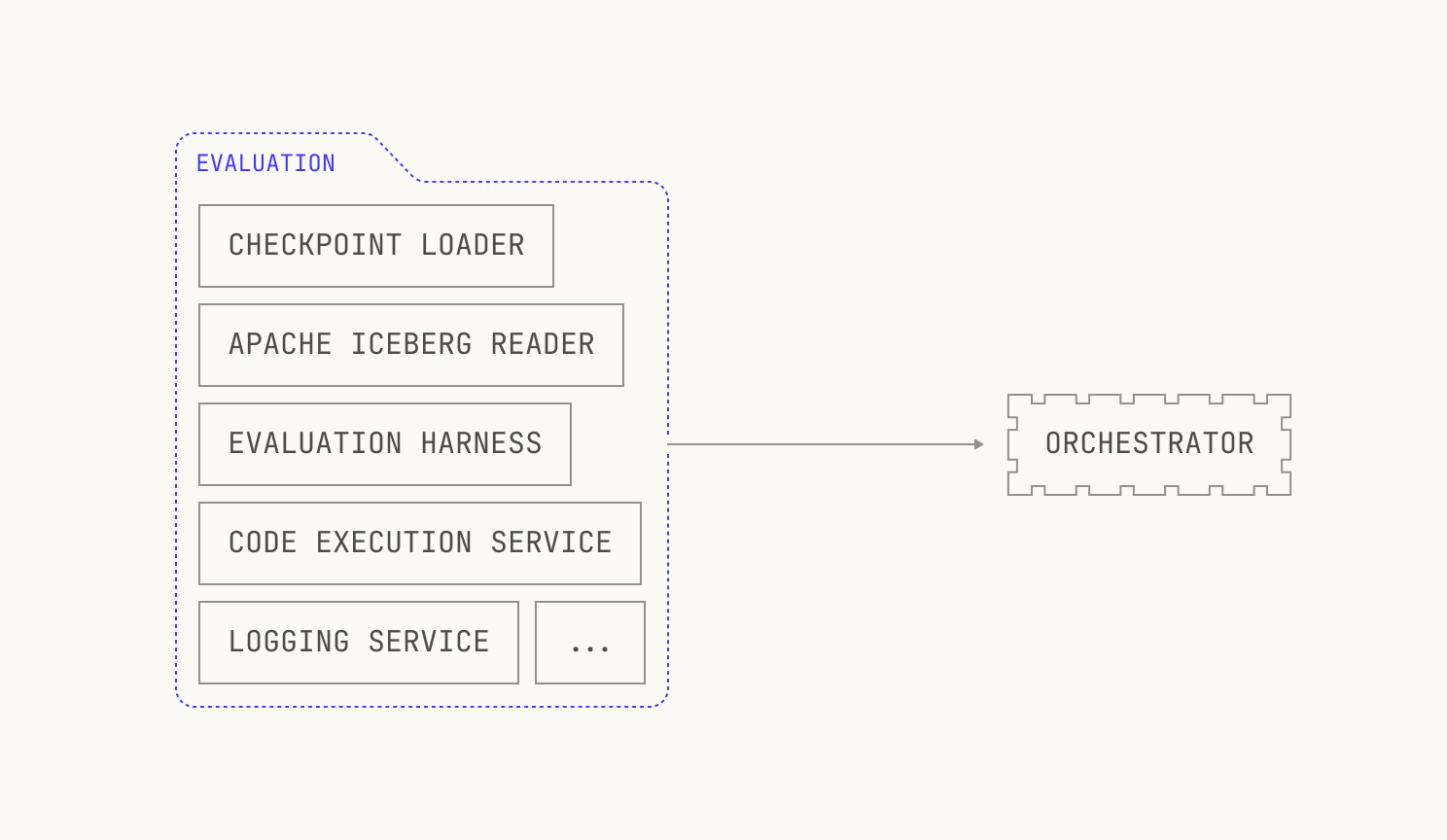
With the discussion on how to implement evaluations out of the way, we can now consider how we'll plug them into the Factory. Running evaluations requires us to run inference, and thus we need to spin up inference deployments quickly. Thankfully, we've already got a way to do this: we can reuse the existing abstractions from our inference service to do this. For workflows against a known checkpoint, like fine-tuning workloads, the abstractions we've already talked about are sufficient. But, for checkpoints that are produced during pre-training, we have a remaining puzzle piece to find: we need to somehow specify which checkpoints to use before they've even been produced. Luckily for us, Dagster has support for this type of workload: the training job can simply push a notification to Dagster that the checkpoint is ready, and the inference jobs will automatically be scheduled. As previously mentioned, each evaluation is scheduled and executes independently, with the outcomes automatically pushed into a Neptune dashboard. This allows not only for easy inspection, but it's also fully automatic; there's typically no need for manual intervention. The only cases where manual intervention is needed, in fact, is if an evaluation fails to run; however, resolving these errors is normally relatively easy, and retriggering failed workflows is normally as simple as clicking a button.
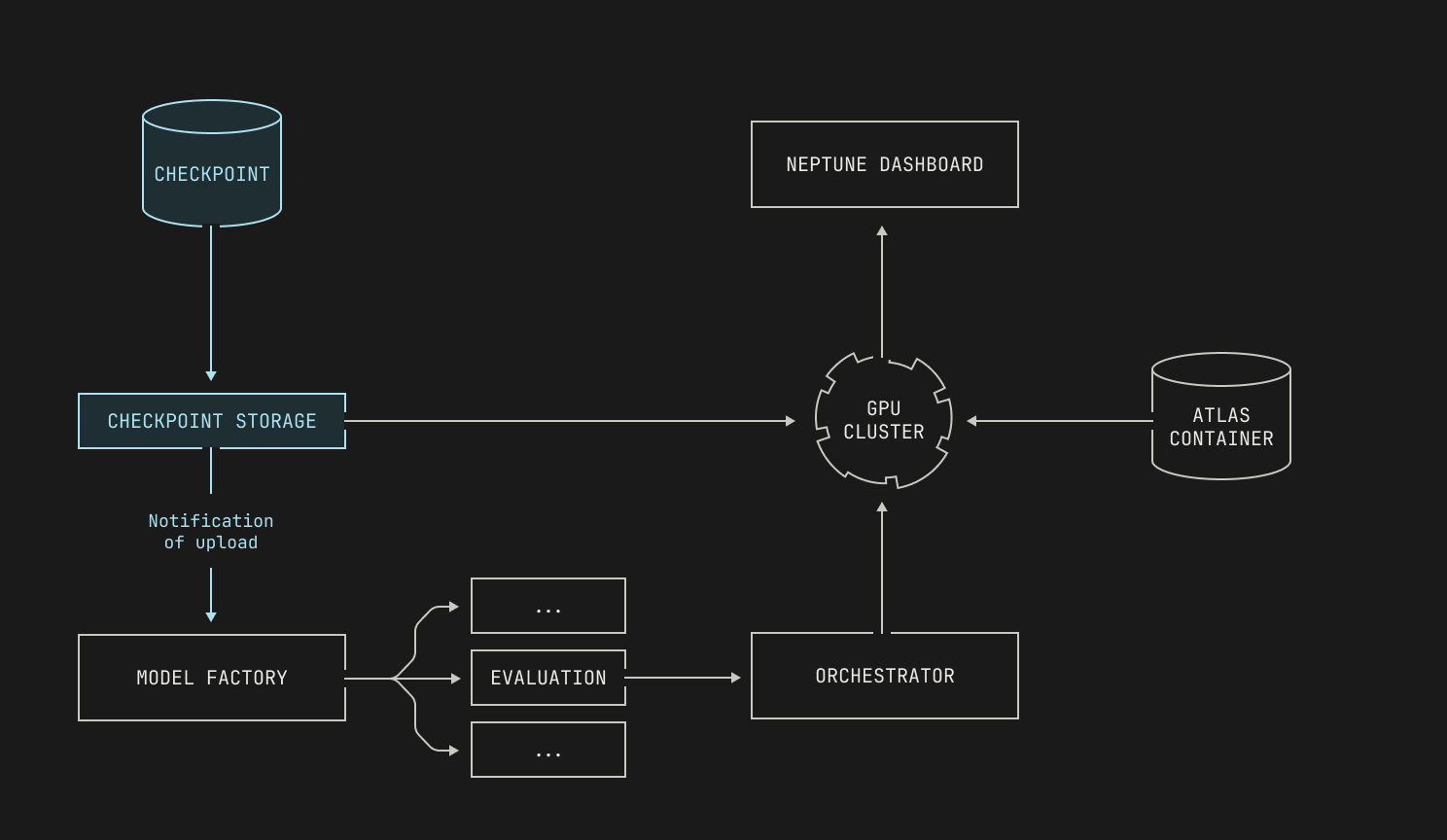
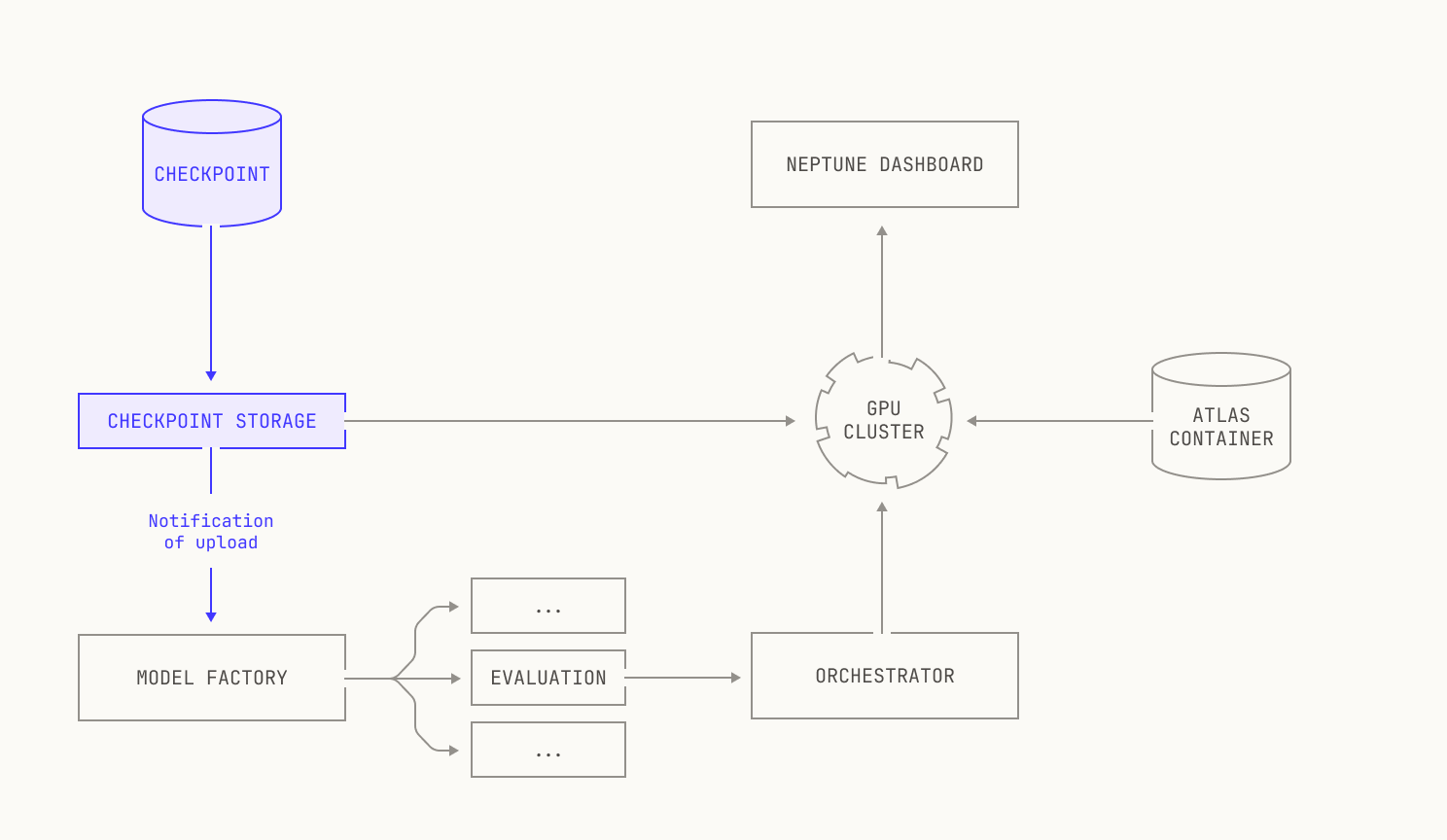
Lastly, we stress that running evaluations at the scale and frequency at our scale would simply be impossible without the facilities provided to us by the Model Factory. Manually running evaluations across checkpoints from different training runs would be a challenge enough, but running evaluations across new checkpoints at different frequencies would be a nightmare. This is even before we consider the task of needing to reserve precious inference-capable nodes for this task, or running different subsets of evaluations on different checkpoints; put simply, it’s highly unlikely that we would ever even attempt to run evaluations. By contrast, the Model Factory makes evaluations so easy to run that there’s simply no reason for us to not use them, either on newly produced checkpoints or as part of a fine tuning or reinforcement learning workflow.
Thank you
We hope you enjoyed reading this post about Atlas and our evaluations pipelines. In our next and final installment, we’ll take a look into the crucial remaining pieces of the Model Factory: fine tuning and reinforcement learning.
Acknowledgements
We would like to thank the foundations, evaluations, infrastructure and production engineering teams at Poolside for their thoughtful insights and comments on this post. We would also like to thank Nvidia, AMD, Annapurna Labs, and Cerebras for their continued collaboration and support.